Nos expertises / Audit performance
Site lent, logiciel qui ralentit : mesurons avant de corriger.
Un problème de performance se diagnostique avec des outils précis, pas au ressenti. Ce qui ne se mesure pas ne se corrige pas : avant toute correction, nous établissons des métriques de référence objectives sur les deux couches qui ralentissent un projet.
Front : score PageSpeed mobile, Core Web Vitals, ressources bloquantes. Back : requêtes SQL lentes, index manquants, processus synchrones à basculer en asynchrone, saturation mémoire et CPU.
Ça vous parle ?
Trois situations qui justifient un audit de performance
Votre score PageSpeed mobile est sous 60 malgré les tentatives d'optimisation
Vous avez compressé des images, installé un plugin de cache, mais les métriques Google ne bougent pas. La cause est souvent structurelle : un framework JS lourd, un TTFB élevé ou des ressources qui bloquent le rendu ne se résolvent pas avec un plugin.
Certaines pages de votre logiciel mettent plusieurs secondes à répondre
Les utilisateurs attendent, le support reçoit des signalements. En production, l'origine est rarement évidente : une seule requête SQL sans index peut bloquer 200 utilisateurs simultanés sur une table de 500 000 lignes.
Votre équipe corrige des lenteurs sans mesures ni plan de priorités
Sans métriques précises, les efforts se concentrent sur ce qui semble lent plutôt que sur ce qui l'est vraiment. Un audit outillé produit une liste de corrections triées par ratio impact/effort.
Performance front
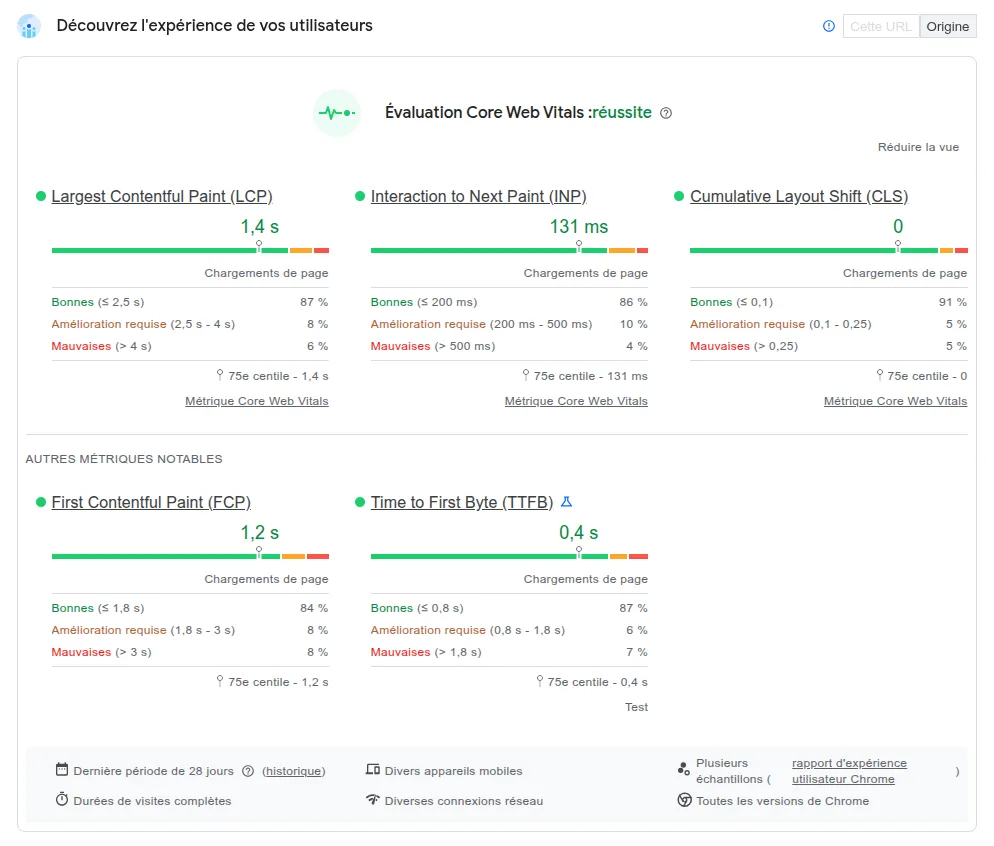
Score PageSpeed et Core Web Vitals : ce que Google mesure vraiment
Google utilise les Core Web Vitals comme facteur de classement depuis mai 2021. Le score mobile est le seul qui compte : Google indexe la version mobile de votre site en priorité, même pour les recherches sur desktop.
Un score sous 50 sur mobile signifie concrètement des pages qui chargent en plus de 3 secondes sur un réseau 4G standard. À ce niveau, 53% des visiteurs mobiles abandonnent avant que la page soit affichée.
- LCP (Largest Contentful Paint)
- Temps d'affichage du plus grand élément visible. Cible : sous 2,5 secondes. Causes fréquentes : image hero non compressée, TTFB élevé, ressources bloquantes.
- INP (Interaction to Next Paint)
- Réactivité aux interactions utilisateur. Cible : sous 200 ms. Dégradé par un JavaScript lourd qui bloque le thread principal.
- CLS (Cumulative Layout Shift)
- Stabilité visuelle pendant le chargement. Cible : sous 0,1. Images sans dimensions, polices web chargées tardivement, publicités qui s'insèrent.
Performance back-end
Requêtes lentes, index manquants et processus bloquants
Un site peut afficher un excellent score Lighthouse et avoir des pages qui mettent 8 secondes à répondre côté serveur. La performance back-end ne se voit pas dans PageSpeed : elle se mesure avec Sentry, Grafana et un profiler PHP.
L'analyse des index de base de données est souvent la correction avec le meilleur ratio impact/effort : ajouter un index sur une colonne mal indexée peut transformer une requête de 2 secondes en une requête de 5 millisecondes, sans modifier une ligne de code métier.
Analyse des plans d'exécution SQL
EXPLAIN ANALYZE révèle ce que la base fait vraiment : full table scan, index non utilisé, coût estimé vs réel. Chaque Seq Scan sur une grande table est un candidat à l'indexation.
Index composites et index inutilisés
Un index composite doit correspondre exactement au pattern de requête (ordre des colonnes inclus). Les index inutilisés ralentissent les écritures sans accélérer aucune lecture.
Cache applicatif et Redis
Identification des requêtes fréquentes sans cache, mise en place de stratégies de cache ciblées. Le cache est une solution pertinente quand la requête ne peut pas être optimisée structurellement.
Processus asynchrones (Symfony Messenger)
Envoi d'emails, génération de PDF, appels API tiers : ces opérations longues exécutées dans une requête HTTP dégradent tous les temps de réponse. Les basculer en file de traitement réduit la latence perçue immédiatement.
Les outils de l'audit
Mesurer avec des outils précis, pas au ressenti
Chaque problème de performance est identifié avec un outil dédié avant d'être recommandé. Pas de correction à l'aveugle : chaque gain est estimé avant d'être engagé.
Lighthouse / PageSpeed Insights
Analyse front gratuite, accessible via URL publique. Score mobile, Core Web Vitals, liste des ressources bloquantes et des opportunités classées par gain estimé.
Sentry
Monitoring des erreurs et transactions en production. Détecte les endpoints les plus lents, les requêtes N+1 et les exceptions récurrentes sur les vraies données de production.
Grafana (Clever Cloud)
Visualisation des métriques infrastructure : temps de réponse, saturation CPU et mémoire, taux d'erreur. Corrèle les pics de charge avec les lenteurs signalées.
Blackfire
Profiling PHP précis en environnement de recette. Graphe d'appels complet, consommation mémoire fonction par fonction, requêtes SQL générées par chaque endpoint.
EXPLAIN ANALYZE
Analyse des plans d'exécution SQL (PostgreSQL et MySQL). Révèle les full table scans, les index manquants et les jointures sous-optimales avec les coûts réels mesurés.
Symfony Profiler
Barre de débogage et profiler intégrés : nombre de requêtes SQL par requête HTTP, temps passé dans chaque service, events, appels Doctrine. Identifie les problèmes N+1 et les services surchargés sans instrumentation externe.
Notre processus d'audit performance
3 étapes pour des corrections actionnables
Un audit efficace produit une liste de corrections priorisées par impact, pas un inventaire de problèmes sans suite.
Étape 1 : Mesure initiale
Établir les métriques de référence
Avant toute correction, nous établissons une base de mesure objective. Cette étape ne nécessite pas forcément d'accès à votre infrastructure : le score PageSpeed est public, Sentry et Grafana suffisent pour un premier état des lieux back-end.
L'objectif est d'obtenir des chiffres précis, pas des impressions : temps de réponse moyen, P95, transactions les plus lentes, pages les plus pénalisées.
Score PageSpeed mobile et desktop
Analyse Lighthouse de vos pages stratégiques : LCP, INP, CLS, TBT, FCP. Identification des ressources qui bloquent le rendu.
Transactions lentes via Sentry
Si Sentry est en place, extraction des endpoints les plus lents, des requêtes N+1 détectées et des erreurs récurrentes en production.
Métriques infrastructure via Grafana
Lecture des dashboards Clever Cloud : saturation CPU et mémoire, temps de réponse moyen, pics de charge et corrélation avec les lenteurs signalées.
Étape 2 : Analyse approfondie
Profiling PHP et plans d'exécution SQL
Cette étape descend au niveau du code et de la base de données. Blackfire génère un graphe d'appels précis : on voit exactement quelle fonction consomme du temps CPU, combien de requêtes SQL sont générées et où la mémoire est gaspillée.
EXPLAIN ANALYZE révèle ce que la base de données fait réellement pour chaque requête lente : full table scan, index non utilisé, jointure sous-optimale. Chaque problème est quantifié avant d'être recommandé.
Profiling Blackfire en recette
Graphe d'appels PHP complet : fonctions les plus coûteuses, nombre de requêtes SQL par page, consommation mémoire. Comparaison avant/après correction.
EXPLAIN ANALYZE sur les requêtes lentes
Analyse du plan d'exécution de chaque requête identifiée : index utilisés ou manquants, coût estimé vs réel, jointures à réécrire.
Analyse des index existants
Inventaire des index en place, détection des index inutilisés (ralentissent les écritures sans accélérer les lectures), identification des index composites manquants.
Revue des processus synchrones
Identification des opérations longues exécutées de façon synchrone dans une requête HTTP : envoi d'emails, génération de PDF, appels API tiers. Candidats à basculer en file de traitement asynchrone.
Étape 3 : Rapport et plan d'action
Corrections classées par impact
Le livrable est un rapport structuré : chaque problème est accompagné de l'impact mesuré (en ms ou en pourcentage de gain estimé), du niveau d'effort et des options de correction disponibles.
Les corrections sont présentées dans l'ordre du meilleur ratio impact/effort : on commence par ce qui change le plus avec le moins de code.
Rapport structuré par priorité
Corrections critiques (gains immédiats), améliorations importantes et optimisations souhaitables : classées pour que vous sachiez par quoi commencer.
Restitution orale
Présentation des résultats avec votre équipe technique pour que chaque recommandation soit comprise et actionnée, pas juste lue.
Corrections prises en charge si besoin
SmartBooster peut prendre en charge les corrections identifiées ou les transmettre à votre équipe avec la documentation nécessaire.
LEXIQUE PERFORMANCE
Les termes de l'audit expliqués
Vocabulaire technique utilisé dans les rapports d'audit et les échanges avec votre équipe.
- Core Web Vitals
- Trois métriques Google mesurant l'expérience utilisateur réelle : LCP (vitesse d'affichage), INP (réactivité aux interactions) et CLS (stabilité visuelle). Utilisées comme signal de classement dans les SERP depuis mai 2021.
- TTFB (Time To First Byte)
- Temps entre l'envoi de la requête HTTP et la réception du premier octet de réponse. Un TTFB élevé signale un problème côté serveur : requête SQL lente, absence de cache, ou traitement applicatif lourd avant de commencer à écrire la réponse.
- Full table scan
- La base de données lit toutes les lignes d'une table pour trouver celles qui correspondent à une requête, faute d'index utilisable. Sur une table de 500 000 lignes, un Seq Scan peut prendre plusieurs secondes là où un index ramène le résultat en quelques millisecondes.
- Index composite
- Index portant sur plusieurs colonnes dans un ordre précis. Son efficacité dépend de l'ordre des colonnes dans la requête : un index (statut, date) n'est pas utilisé par une requête qui filtre uniquement sur date. L'analyse du plan d'exécution révèle les cas où l'index est présent mais ignoré.
- Profiling
- Mesure du temps passé dans chaque fonction ou service pendant l'exécution d'une requête. Contrairement aux logs, le profiling capture l'ensemble de la pile d'appels : il révèle les goulots d'étranglement invisibles à la seule lecture du code.
- Requête N+1
- Pattern où une requête principale charge une liste de N entités, puis exécute une requête supplémentaire pour chacune. Pour 100 enregistrements, 101 requêtes sont envoyées à la base. Une jointure ou un chargement groupé (Doctrine: fetch JOIN) ramène cela à 1 ou 2 requêtes.
- File de traitement (queue)
- Mécanisme qui délègue une opération longue (envoi d'email, génération de PDF, appel API tiers) à un processus en arrière-plan. La requête HTTP répond immédiatement, sans attendre la fin du traitement. Symfony Messenger est l'implémentation standard dans les projets SmartBooster.
- Thread principal
- Fil d'exécution unique du navigateur qui gère à la fois le rendu, le JavaScript et les interactions utilisateur. Un script JS lourd qui s'exécute sur le thread principal bloque l'affichage et les clics pendant son exécution, dégradant l'INP et le LCP.
Pour aller plus loin
Approfondir votre réflexion
Votre logiciel est lent mais aussi vieillissant ou mal structuré ? L'audit technique couvre l'architecture, la dette, la sécurité et la couverture de tests.
Tests automatisés, CI/CD et outils d'analyse statique : la qualité du code prévient les régressions de performance à chaque déploiement.
Si votre site ne peut plus évoluer techniquement, deux approches permettent d'ajouter de la logique métier sans refonte complète.
PARLONS DE VOTRE PROJET
Vous savez que votre site ou logiciel est lent. Voyons ce qui l'est vraiment.
Apportez votre score PageSpeed, vos logs Sentry ou simplement une description de la lenteur constatée. En échangeant sur votre contexte, nous identifions les axes d'analyse les plus pertinents avant même d'ouvrir un outil.
Échange sans engagement → Rapport priorisé sous 5 jours

FAQ
Les réponses à vos questions
Et si vous ne trouvez pas ce que vous cherchez, nous serons ravis de vous répondre en direct lors d'un rendez-vous entre humains !
Un index manquant sur une colonne utilisée dans une clause WHERE ou JOIN force la base de données à parcourir toutes les lignes de la table. Sur 100 000 enregistrements, cela peut transformer une requête de 5 ms en une requête de 2 000 ms. L'outil EXPLAIN ANALYZE révèle ces scans séquentiels : chaque Seq Scan sur une grande table est un candidat à l'indexation. pg_stat_user_indexes (PostgreSQL) permet également d'identifier les index existants qui ne sont jamais utilisés et ralentissent les écritures pour rien.
L'audit technique évalue la qualité, la maintenabilité et la sécurité du code : architecture, dette technique, couverture de tests, vulnérabilités CVE. L'audit performance se concentre sur la vitesse mesurable : temps de chargement des pages, requêtes SQL lentes, saturation des ressources serveur. Les deux sont complémentaires : une application bien architecturée peut être lente pour des raisons de requêtes ou de cache, et une application rapide peut accumuler une dette technique invisible.
Partiellement. Le score PageSpeed est accessible sans aucun accès : une URL publique suffit. Pour l'analyse back-end, l'accès à Sentry (si configuré) et à Grafana permet d'identifier les transactions lentes et les pics de charge sans accès direct au serveur. EXPLAIN ANALYZE nécessite un accès base de données, mais peut être réalisé sur un environnement de recette avec des données de volume équivalent à la production.
Un audit front (PageSpeed, Core Web Vitals) se réalise en une demi-journée. Un audit complet incluant l'analyse des requêtes SQL lentes, le profiling Blackfire et la revue des processus asynchrones prend 1 à 3 jours selon la taille de l'application et les accès disponibles.
Le cache traite les symptômes, pas toujours les causes. Mettre en cache le résultat d'une requête qui prend 3 secondes améliore l'expérience pour le second appel, mais ne résout pas le problème structurel. L'audit distingue trois niveaux : la requête elle-même (un index manquant suffit souvent à la diviser par 10), la logique applicative qui l'appelle (une boucle qui exécute 50 requêtes là où une jointure suffit, c'est un problème algorithmique que le cache ne corrige pas), et le volume de données traité inutilement (filtrage trop tardif, chargement de colonnes non utilisées). Dans de nombreux cas, optimiser l'algorithme ou ajouter un index résout le problème définitivement, sans cache.
Les deux. Le rapport liste chaque problème avec son impact mesuré, l'effort estimé pour le corriger et les options disponibles. Les corrections sont priorisées : certains gains (index manquant, cache d'une requête fréquente) s'implémentent en moins d'une heure et peuvent diviser les temps de réponse par dix.
Vous avez un projet ?
Contactez-nous pour savoir comment nous pouvons vous aider.