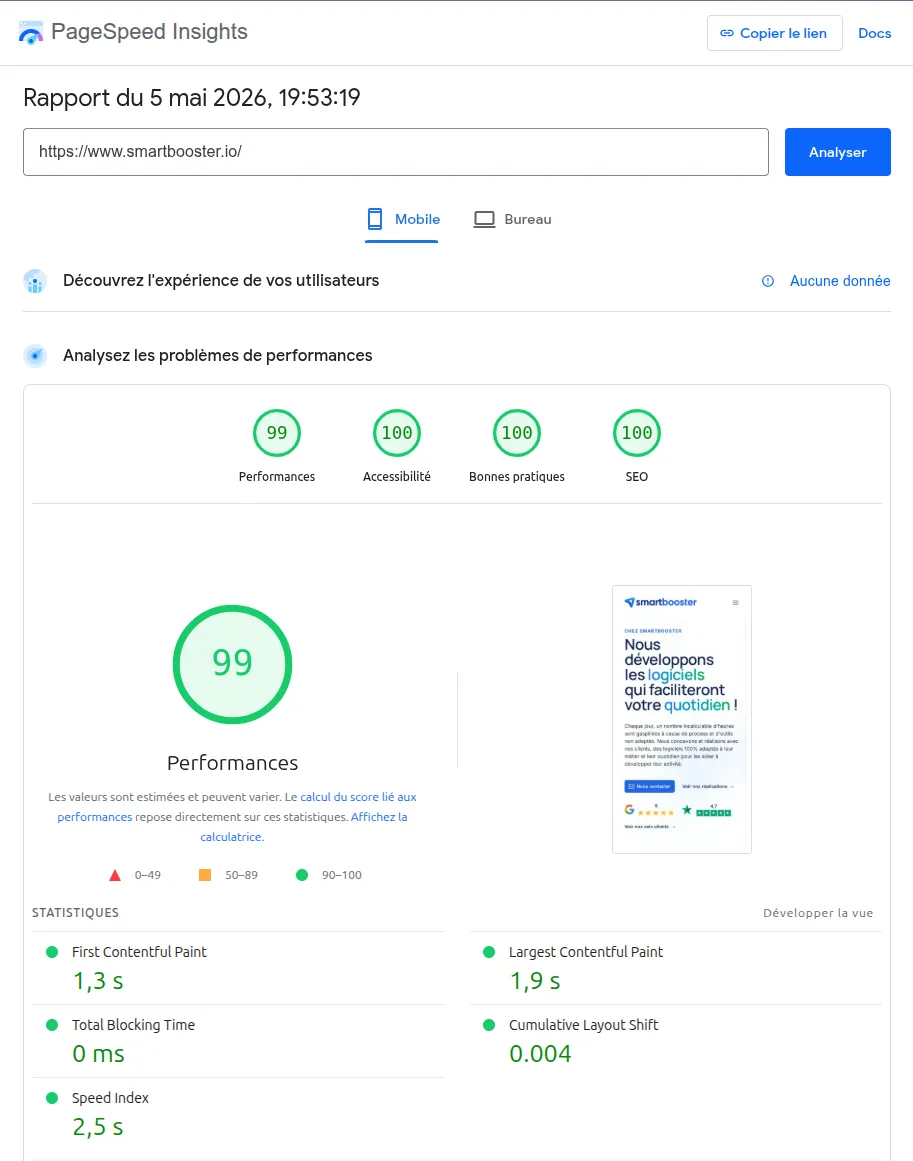
Google AI Overviews, Perplexity, ChatGPT Search, Claude : ces systèmes ne renvoient plus des listes de liens bleus. Ils lisent le web, synthétisent et génèrent une réponse directe. Votre site peut être cité, résumé et recommandé… ou ignoré.
Cette mutation a un nom : le GEO (Generative Engine Optimization). Là où le SEO consiste à se positionner dans les résultats classiques de Google, le GEO vise à être sélectionné comme source pertinente dans les réponses générées par ces nouveaux moteurs. Les leviers sont différents, les règles du jeu aussi.
L’un de ces leviers est particulièrement accessible : le fichier llms.txt. Si vous connaissez robots.txt, l’analogie est
immédiate. Là où robots.txt dit aux crawlers ce qu’ils ont le droit de faire, llms.txt dit aux IA ce qu’elles ont besoin
de comprendre. L’un contrôle l’accès, l’autre guide la compréhension.
De robots.txt à llms.txt : un changement de registre
robots.txt date de 1994. Il répond à une question binaire : ce crawler peut-il accéder à cette URL ? sitemap.xml, apparu en
2005, répond à une question d’inventaire : quelles URLs existent et quand ont-elles changé ? Ces deux fichiers parlent la langue
des moteurs classiques.
Le llms.txt, proposé par Jeremy Howard (cofondateur de fast.ai) et formalisé sur
llmstxt.org, répond à une question radicalement
différente : que fait ce site, et quels contenus méritent d’être compris en priorité ? Ce n’est ni un mécanisme de permissions,
ni un inventaire technique. C’est un guide sémantique, rédigé en Markdown, destiné à des systèmes qui raisonnent sur le texte.
Pourquoi le HTML est un problème pour les IA
Quand un LLM tente de comprendre un site, il doit parser du HTML. Menus de navigation, footers, pop-ups, scripts de tracking, attributs CSS : le signal pertinent se noie dans le bruit structural. Les informations importantes sur votre activité coexistent avec des dizaines de balises qui n’ont aucune valeur sémantique.
Le Markdown pur, lui, est traité avec une précision nettement supérieure. Il préserve ce qui compte : titres, listes, liens, texte.
Un fichier llms.txt bien structuré permet à un LLM de comprendre qui vous êtes et ce que vous faites en quelques secondes de
lecture, sans avoir à inférer l’essentiel derrière la structure HTML d’une page de marketing.
llms.txt et llms-full.txt : deux niveaux, deux usages
La spécification prévoit deux fichiers complémentaires.
llms.txt est un index résumé. Il contient le nom du site, une description en une ou deux phrases, et des sections de liens
vers les contenus clés, chacun accompagné d’une description factuelle. Les contenus secondaires se regroupent dans une section
## Optional : les modèles à fenêtre de contexte réduite peuvent l’ignorer et se concentrer sur l’essentiel.
llms-full.txt est une base de connaissances complète. Il concatène le contenu Markdown de toutes les pages référencées
en un seul document, destiné aux modèles capables de traiter de longs contextes. Perplexity et certains modes de ChatGPT
l’exploitent lorsqu’il existe. Votre contenu complet est ainsi accessible sans que le crawler ait à visiter chaque page
individuellement.
La règle de priorisation est simple : ce qui doit être cité en priorité se place en haut du llms.txt, hors section Optional.
Implémenter llms.txt : technique simple, contenu stratégique
La bonne nouvelle : la mise en place technique est assez simple. Le llms.txt est un fichier texte, servi à une URL connue.
Aucun framework particulier n’est requis, aucune dépendance à installer.
Sur un site Astro, le plus simple est de placer le fichier dans public/. Tout fichier dans ce répertoire est servi
tel quel par le build, sans transformation. Accessible à /llms.txt dès le premier déploiement.
public/
llms.txt ← accessible dès le déploiement, aucune config
llms-full.txt ← optionnel, pour les modèles à grand contexte
robots.txtSur un projet Symfony, même principe : un fichier dans public/ est servi directement par le serveur web (Nginx,
Apache, ou Static Web Server). Si vous préférez générer le contenu dynamiquement, un contrôleur dédié retourne une Response
avec le content-type text/plain et construit le Markdown depuis vos entités (services, réalisations, articles de blog).
Utile quand vos offres évoluent fréquemment et que vous ne voulez pas maintenir le fichier à la main.
Un llms.txt désynchronisé est contre-productif : il induit les IA en erreur sur votre activité. Si vous optez pour
la version statique, planifiez sa mise à jour à chaque évolution significative du site.
Mais la vraie difficulté n’est pas là. Mettre un fichier en ligne prend une heure. Décider ce qu’il doit contenir est
un exercice éditorial qui demande de la réflexion. C’est cette partie qui fait la différence entre un llms.txt utile
et un fichier que les IA ignorent faute de signal clair.
Rédiger un llms.txt efficace
Voici un exemple minimal conforme à la spécification :
# SmartBooster
> Agence de développement de logiciels sur mesure pour les TPE et PME.
> Symfony, Vue.js, automatisation des processus métier.
## Expertises
- [Développement logiciel sur mesure](https://www.smartbooster.io/expertise/developpement-logiciel-sur-mesure/):
Conception d'applications métier adaptées aux processus des PME.
- [TMA et maintenance évolutive](https://www.smartbooster.io/expertise/tma-maintenance-logiciel-evolutive/):
Faire évoluer et maintenir un logiciel existant dans la durée.
- [Prototype MVP](https://www.smartbooster.io/expertise/prototype-mvp-logiciel/):
Valider une idée produit avant d'investir dans le développement complet.
## Optional
- [Blog](https://www.smartbooster.io/blog/): Conseils et retours d'expérience sur le développement logiciel.Quelques règles à respecter :
-
Privilégier les liens absolus. La spécification recommande les URLs complètes avec
https://pour que le modèle puisse naviguer sans avoir à deviner la racine du site. -
Exclure ce qui dilue. Mentions légales, pages de confirmation de formulaire, contenus en double, landing pages vides : chaque entrée superflue diminue la qualité du signal. Un
llms.txtde vingt entrées bien choisies vaut mieux qu’un inventaire de cent liens. Pensez-le comme un README de votre présence web : il doit permettre à un système intelligent de comprendre votre activité en trente secondes. -
Ne jamais y inclure des données sensibles ou concurrentiellement stratégiques : méthodologies internes non publiées, données de pricing, accès à des outils internes. Vous invitez volontairement les IA à lire et citer ce contenu : choisissez consciemment ce que vous voulez qu’elles retiennent.
Mesurer l’impact
Les outils classiques (Search Console, Plausible) ne tracent pas les citations dans les moteurs génératifs. L’impact reste difficile à quantifier précisément, mais plusieurs approches sont praticables dès aujourd’hui :
- Interroger Perplexity, ChatGPT Search et Claude sur des requêtes liées à votre activité et observer si votre site est cité, avec quelle précision
- Surveiller dans vos logs serveur les User-Agents des crawlers IA : GPTBot (OpenAI), ClaudeBot (Anthropic), PerplexityBot,
Amazonbot ; vérifier qu’ils accèdent bien à
/llms.txt - Comparer la qualité des réponses générées sur votre activité avant et après la mise en place du fichier
C’est encore artisanal. Mais la fenêtre pour se positionner tôt est ouverte, et elle ne le restera pas indéfiniment.
Ce que ça change pour votre visibilité
Le SEO classique ciblait des moteurs qui indexent des pages et renvoient des liens. Les moteurs génératifs fonctionnent différemment : ils construisent une réponse à partir de plusieurs sources et les citent, ou non, selon la confiance accordée au contenu source.
Un site structuré pour les LLM, avec un llms.txt cohérent et un contenu Markdown accessible, a davantage de chances d’être
sélectionné comme source pertinente dans ces réponses. Ce n’est pas une garantie, mais c’est un levier que la plupart de vos
concurrents n’ont probablement pas encore activé.
Le llms.txt n’est pas un gadget technique. C’est l’équivalent, pour l’ère des moteurs génératifs, de ce que le sitemap.xml
représentait pour les moteurs classiques : un signal structuré adressé aux systèmes qui construisent la réponse à la place du clic.
Nous utilisons l’IA au quotidien dans notre workflow, notamment Claude Code pour accélérer nos
développements. Le llms.txt est une des briques de visibilité que nous recommandons d’implémenter maintenant plutôt
d’attendre sa généralisation. Si votre site mérite d’être cité par les moteurs de demain, la mise en place est affaire de quelques
heures. Parlez-nous de votre projet.