Un RAG (Retrieval-Augmented Generation) est un système qui vous permet de créer votre propre assistant IA dont les réponses se baseront sur votre base de connaissances.
Dans cet article, nous allons aborder l’aspect technique de la création de cette “base de connaissance” dans un format directement consommable par un LLM que l’on appelle les embeddings.
Cette étape de création et d’indexation des embeddings pose les bases de votre système. C’est elle qui conditionne 80 % de la qualité des réponses que vous obtiendrez.
Dans cet article, nous allons aborder :
- ce qu’est concrètement un embedding et pourquoi l’indexation est indispensable au RAG ?
- comment choisir et nettoyer ses sources avant d’embedder ?
- les stratégies de découpage selon le type de contenu
- l’overlap, l’enrichissement contextuel et les métadonnées
- trois niveaux d’implémentation par difficulté
1. Qu’est-ce que l’indexation des embeddings ?
Embeddings, indexation : deux termes, une chaîne
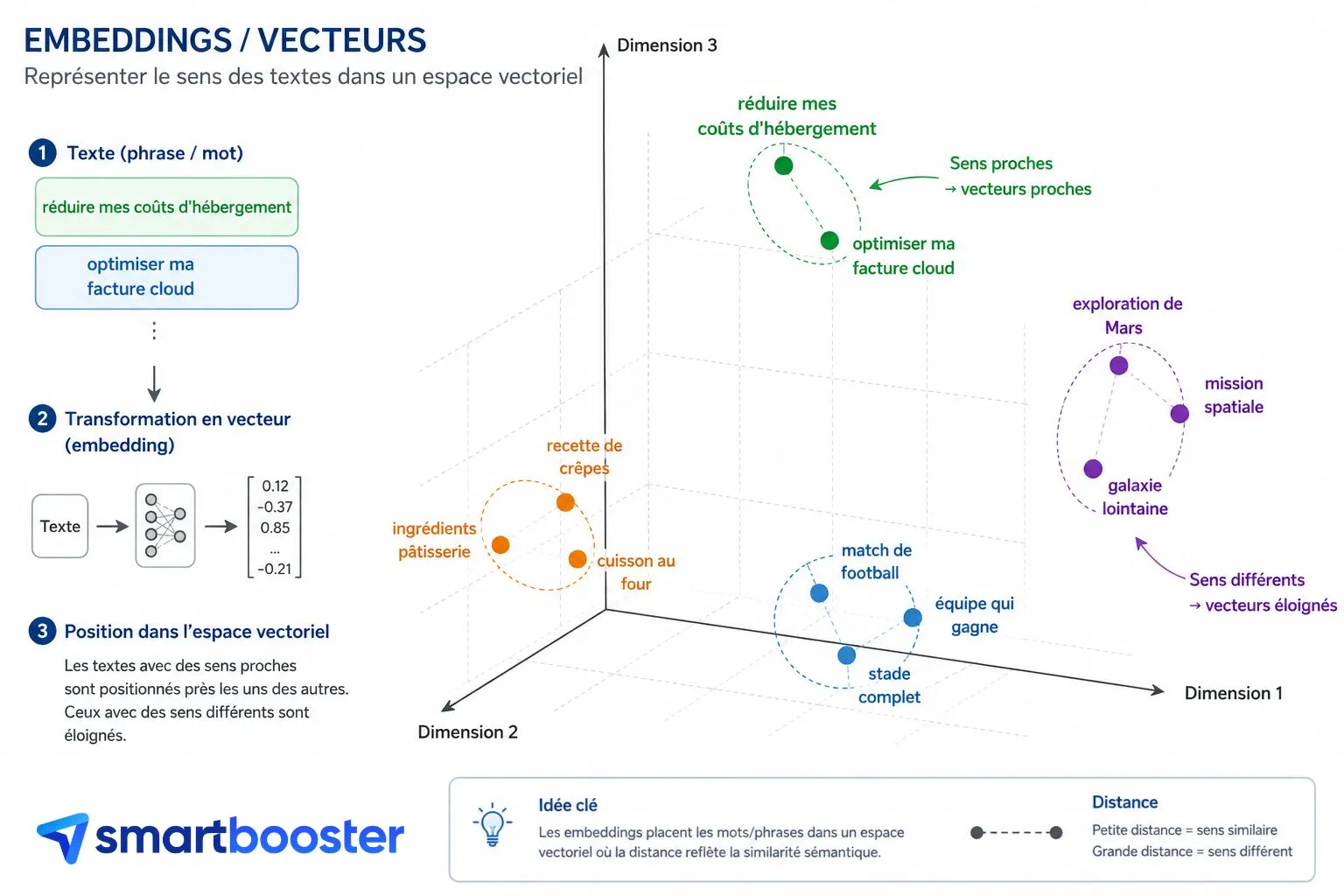
Un embedding est une représentation numérique d’un texte sous forme d’un vecteur de plusieurs centaines, voire plusieurs milliers de nombres. Deux textes qui parlent de la même chose ont des vecteurs proches dans cet espace, même s’ils n’utilisent aucun mot en commun. C’est ce qui permet à un système de comprendre que « réduire mes coûts d’hébergement » et « optimiser ma facture cloud » parlent du même sujet.
Le schéma suivant vous explique le concept de manière plus visuelle : les embeddings placent les mots/phrases dans un espace
vectoriel où la distance reflète la similarité sémantique.
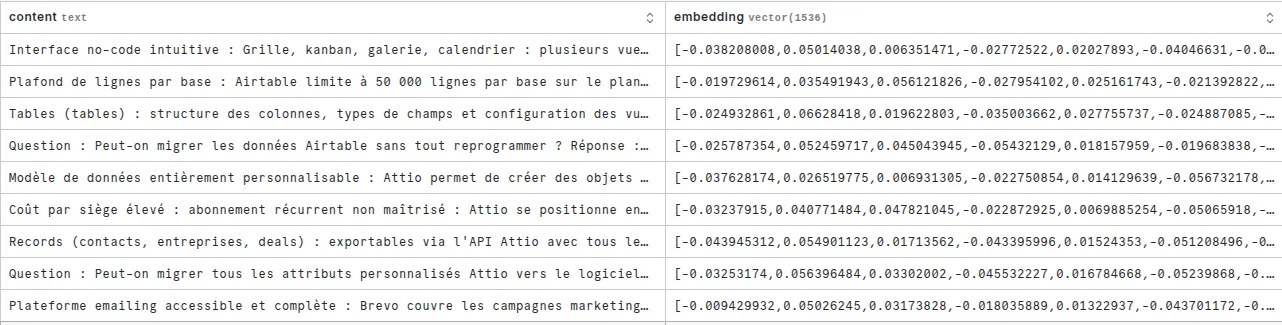
L’indexation consiste à appliquer cette transformation à l’ensemble du corpus de connaissances qu’on veut interroger, puis à stocker chaque vecteur avec son texte d’origine. On obtient au final un index vectoriel : une structure qui associe à chaque morceau de contenu sa signature sémantique.
Exemple de table de correspondance entre contenu et embedding :
Pourquoi c’est nécessaire pour un RAG
Un LLM seul ne connaît pas votre contenu. Pour qu’il puisse répondre à partir de votre base documentaire, il faut, au moment de
la question, retrouver les passages pertinents et les lui injecter en contexte. Cette recherche ne peut pas être un simple
grep mot-clé : l’utilisateur ne devine pas le vocabulaire exact du document. Il pose sa question avec ses mots à lui.
C’est exactement le problème que résout la recherche vectorielle : comparer le sens de la question au sens des passages, pas les mots exacts. Mais pour pouvoir comparer en temps réel, il faut que tous les passages aient été pré-transformés en vecteurs en amont. C’est l’indexation.
flowchart TD
subgraph Indexation["Phase 1 — Indexation (hors-ligne)"]
direction TB
Src[Sources de contenu]
Clean[Nettoyage + découpage]
Chunks["Passage de texte (appelé Chunk)"]
Embed[Modèle d'embedding]
Idx[(Index vectoriel)]
Src --> Clean --> Chunks --> Embed --> Idx
end
subgraph Recherche["Phase 2 — Recherche (à chaque question)"]
direction TB
Q[Question utilisateur]
EmbedQ[Modèle d'embedding]
Search[Recherche vectorielle]
Top["Retourne les meilleurs résultats (Top-K)"]
LLM[Appel au LLM génératif avec : Prompt Système + Question utilisateur + Top-K chunks]
Resp[Génére la Réponse]
Q --> EmbedQ --> Search --> Top --> LLM --> Resp
end
Idx -.consultée par.-> Search
Les deux phases sont complètement découplées dans le temps. L’indexation est un batch, qui peut prendre quelques minutes à plusieurs heures selon le volume. La recherche, elle, doit répondre en quelques centaines de millisecondes. Cette séparation est fondamentale : tout ce qu’on peut faire pendant l’indexation (nettoyer, structurer, enrichir) évite d’avoir à le faire à chaque requête.
2. La source du contenu : ce qui détermine 80 % du résultat
L’index vectoriel est une projection fidèle de ce qu’on lui donne en entrée. Si la matière première est de mauvaise qualité ou mal choisie, aucun modèle d’embedding, aussi performant soit-il, ne corrigera le tir. Le principe du « garbage in, garbage out » s’applique au RAG : un mauvais chunk pollue l’index pour la durée de vie du système.
Cibler les bonnes sources
La tentation est de tout indexer : « plus il y a de contenu, plus le RAG répondra ». C’est faux. Plus il y a de contenu non pertinent, plus le risque de récupérer le mauvais passage au moment de la requête augmente. Le score de similarité ne distingue pas un passage faisant autorité d’un brouillon obsolète.
Quelques règles pragmatiques pour qualifier une source :
- A-t-elle une vocation à être lue ? Une page de documentation publique, un article de blog, une FAQ, oui. Un export brut d’une base de données, un email interne, un PDF de présentation commerciale truffé de visuels, généralement non.
- Est-elle à jour ? Un contenu obsolète qui contredit un contenu récent va polluer toutes les réponses sur le sujet.
- Apporte-t-elle de l’information unique ? Indexer 15 articles qui paraphrasent le même contenu va diluer le signal sans rien ajouter à la connaissance disponible.
La phase de nettoyage : retirer tout ce qui n’est pas nécessaire
Tout texte destiné à être embeddé doit être réduit à son signal sémantique pur. Tout le reste, c’est du bruit qui va déformer le vecteur et faire baisser la précision de la recherche.
Ce qui doit disparaître :
- Les éléments de structure HTML résiduels (balises, attributs, scripts inline)
- Les éléments de navigation (menus, breadcrumbs, footers)
- Les éléments visuels remplacés par leur alt text si pertinent, supprimés sinon
- Les blocs récurrents (bandeaux RGPD, CTA, encarts newsletter, signatures d’articles)
- Les URLs brutes (sauf si elles portent une info utile, ex. un nom de produit)
- Le contenu généré par l’éditeur sans contrôle (commentaires utilisateurs, par exemple)
Cette phase n’est pas glamour mais c’est elle qui transforme un corpus brut en corpus exploitable. Sur un site contenu-riche, le ratio « bruit / signal » d’une page HTML peut facilement dépasser 50 %.
Et c’est vous pouvez suivre le même principe pour les autres formats de contenu : Word, PDF, Markdown…
Une stratégie de découpage par type de source
Toutes les sources ne se découpent pas de la même façon. Un article de blog se découpe naturellement par section, une FAQ par question, une fiche produit par groupe d’attributs. Adopter une stratégie uniforme (« on coupe tous les 500 mots ») revient à ignorer la structure réelle du contenu et à casser des unités de sens.
flowchart TB
Src[Source]
Type{Type de contenu ?}
Body[Document long<br/>article, doc, guide]
Faq[Q/R<br/>FAQ, support]
Struct[Données structurées<br/>fiche produit, profil]
H2[Découpage par titre<br/>de section]
QA[Un chunk par<br/>paire question/réponse]
Group[Un chunk par<br/>groupe d'attributs]
Out[(Chunks normalisés)]
Src --> Type
Type -->|long| Body --> H2 --> Out
Type -->|q/r| Faq --> QA --> Out
Type -->|structuré| Struct --> Group --> Out
Le format de sortie reste uniforme : chaque chunk est un objet avec un identifiant stable, le texte propre, la collection d’origine, l’URL canonique et un bloc de métadonnées. Cette standardisation permet de traiter ensuite tous les chunks de la même manière, quelle que soit leur source.
3. Comment mettre en place l’indexation ?
Le chunk : l’unité de base d’un index
Un chunk est un morceau de texte de taille raisonnable, suffisamment court pour être embeddé en une fois et suffisamment long pour porter du sens à lui seul. C’est l’unité atomique de votre index : ce qui sera comparé à la question utilisateur et qui sera injecté dans le prompt si la similarité est suffisante.
Deux contraintes encadrent le choix de la taille d’un chunk :
- Trop court : le chunk n’a pas assez de contexte. Un paragraphe isolé peut être ambigu, manquer le sujet de la section ou renvoyer une similarité trompeuse parce qu’il contient le mot-clé sans porter l’information.
- Trop long : le chunk est sémantiquement « flou ». Si un texte couvre plusieurs sous-sujets, son vecteur sera un compromis entre tous : aucun ne sera vraiment détectable à la recherche.
En pratique, une fourchette de 200 à 800 tokens (l’équivalent grossier de 150 à 600 mots français) couvre la majorité des cas.
La taille de contexte des modèles d’embedding
Chaque modèle d’embedding a une fenêtre de contexte maximale : la quantité de texte qu’il peut transformer en un seul vecteur. Quelques ordres de grandeur courants :
- Modèles « légers » d’OpenAI (
text-embedding-3-small,text-embedding-3-large) : 8 192 tokens - Modèles open source de type
bge-m3,qwen3-embedding: entre 8 192 et 32 768 tokens selon les versions - Modèles plus anciens (
text-embedding-ada-002) : 8 192 tokens également
Cette limite est un plafond technique. Embedder un texte de 7 000 tokens dans un seul vecteur produit toujours quelque chose, mais la qualité sémantique du résultat se dégrade bien avant la limite. Un vecteur unique ne peut pas représenter fidèlement un document de 20 pages couvrant 12 sujets différents.
La règle pragmatique : la fenêtre maximale est un plafond, pas une cible. Pinecone, dans son article de référence Chunking Strategies for LLM Applications, documente une zone de test typique allant de 128 à 1 024 tokens, à calibrer empiriquement selon le contenu. Tous restent largement en dessous de la fenêtre maximale des modèles (8 192 tokens et plus).
L’overlap : éviter de casser le sens aux frontières
Quand on découpe un texte long en chunks, on risque de couper au milieu d’un raisonnement. La phrase qui contient la réponse à la question utilisateur peut se trouver à cheval sur deux chunks, dont aucun pris isolément ne déclenchera une bonne similarité.
L’overlap (chevauchement) consiste à inclure les dernières lignes du chunk N au début du chunk N+1. Ainsi, l’information à la frontière apparaît dans deux chunks et a deux occasions d’être retrouvée.
flowchart LR
Doc["Texte source<br/>(document long)"]
subgraph Sans["Sans overlap"]
C1A["Chunk 1<br/>tokens 0 → 500"]
C2A["Chunk 2<br/>tokens 500 → 1000"]
C3A["Chunk 3<br/>tokens 1000 → 1500"]
end
subgraph Avec["Avec overlap (50 tokens)"]
C1B["Chunk 1<br/>tokens 0 → 500"]
C2B["Chunk 2<br/>tokens 450 → 950"]
C3B["Chunk 3<br/>tokens 900 → 1400"]
end
Doc --> Sans
Doc --> Avec
Un overlap typique se situe entre 10 % et 20 % de la taille du chunk. Trop peu, on n’attrape pas les frontières. Trop, on augmente artificiellement la taille de l’index et on récupère plusieurs fois la même information dans le top-K à la recherche.
L’overlap n’est utile que pour les chunks découpés mécaniquement dans un texte long. Si le découpage suit la structure du document (un chunk par section, par question de FAQ, par groupe d’attributs), l’overlap n’a généralement pas de sens : les frontières sont déjà sémantiquement propres.
Enrichir le texte avant de l’embedder
Le texte qu’on envoie au modèle d’embedding n’est pas obligatoirement le texte affiché à l’utilisateur final. On peut, et on devrait, l’enrichir avec son contexte.
Un paragraphe sur « les étapes clés » n’a aucun sens hors de son article. En revanche, si on préfixe ce paragraphe par le titre de l’article et le titre de la section avant de l’embedder, le vecteur résultant porte bien plus d’information. Une question comme « comment lancer un projet SaaS » va correctement matcher le chunk, même si le mot « projet SaaS » n’apparaît pas dans le paragraphe lui-même.
Un format typique : [collection] Titre de l'article | Titre de section : contenu du chunk. Le contenu original reste inchangé
en stockage, mais ce qui est embeddé porte la signature complète.
Cet enrichissement peut aussi être porté par des métadonnées attachées au chunk plutôt que concaténées dans le texte embeddé : type de contenu, audience cible, date, tags, langue, niveau d’autorité de la source. Ces champs ne participent pas au calcul de similarité, mais ils ouvrent deux usages au moment de la recherche : filtrer en amont (ne chercher que dans les FAQ produit, ou exclure les contenus obsolètes) et présenter une réponse plus riche à l’utilisateur (afficher la source, la date, le contexte). Les deux approches, préfixe textuel et métadonnées, sont complémentaires : l’une nourrit le vecteur, l’autre nourrit la requête et l’affichage.
4. Trois niveaux d’ambition : par où commencer ?
Toutes les approches précédentes peuvent être mises en place à des niveaux de sophistication très différents. Comprendre où l’on se situe permet de prioriser les efforts.
Niveau simple : faire tourner un premier RAG en quelques heures
On indexe ce qu’on a, comme on l’a. Découpage mécanique tous les N tokens, pas d’overlap, pas d’enrichissement, pas de nettoyage poussé. Toutes les sources passent par le même pipeline.
C’est suffisant pour un POC, une démo interne ou pour valider que le couple « modèle d’embedding + base de connaissances » a un intérêt sur les questions cibles. C’est insuffisant en production : la qualité des réponses sera aléatoire, surtout sur les questions qui touchent des passages frontières ou des contenus structurés.
Niveau intermédiaire : adapter le découpage à la source
On distingue les types de sources et on applique une stratégie de découpage par type (par section pour les articles, par Q/R pour les FAQ, par groupe d’attributs pour les fiches structurées). On nettoie le contenu en amont. On enrichit les chunks avec leur contexte ou via metadata avant embedding. On filtre les chunks trop courts (typiquement moins de 80 caractères) pour éviter le bruit dans l’index.
C’est le palier de production raisonnable pour la majorité des cas d’usage B2B. La précision de la recherche fait un saut net par rapport au niveau simple, sans complexité d’ingénierie disproportionnée.
C’est le niveau que nous utilisons chez SmartBooster.
Niveau avancé : exploiter la sémantique pour découper et hiérarchiser
On utilise un LLM pour identifier les ruptures sémantiques d’un document et découper sur ces frontières (« semantic chunking »). On met en place un index hiérarchique : un chunk « parent » résume une section entière, des chunks « enfants » couvrent les détails. La recherche cible d’abord les parents pour identifier le bon territoire, puis affine sur les enfants. On enrichit chaque chunk de métadonnées exploitables au moment de la requête (date, type de contenu, audience cible) pour permettre des filtres en plus du score de similarité.
C’est utile sur des corpus volumineux, hétérogènes, ou quand la précision attendue est très élevée (support produit critique, recherche juridique, base de connaissances réglementaire). C’est aussi un effort d’ingénierie significatif qui ne se justifie que si les niveaux précédents ont été poussés à leurs limites.
flowchart TB
Start([Indexation à mettre en place])
Start --> Q1{Volume de contenu ?}
Q1 -->|< 100 documents,<br/>POC, démo| Simple[Niveau simple]
Q1 -->|Corpus production<br/>hétérogène| Q2{Sources structurées ?}
Q2 -->|Mix articles,<br/>FAQ, fiches| Inter[Niveau intermédiaire]
Q2 -->|Corpus volumineux<br/>précision critique| Avance[Niveau avancé]
Simple -.suffit pour valider.-> End([En production])
Inter -.bon défaut.-> End
Avance -.cas exigeants.-> End
La progression entre niveaux n’est pas obligatoire : un projet peut très bien rester en niveau intermédiaire pendant des années sans jamais avoir besoin d’aller plus loin. L’inverse est plus risqué : passer en production avec un niveau simple, c’est accepter de devoir reconstruire l’index plus tard.
Pour aller plus loin
L’indexation des embeddings n’est qu’une brique d’un système RAG complet. Pour que l’ensemble fonctionne, il faut encore choisir une base vectorielle adaptée au volume et au profil de requête, calibrer le top-K et le seuil de similarité au moment de la recherche, gérer les coûts d’embedding et d’inférence dans la durée, et mettre en place une boucle d’observabilité pour mesurer la qualité réelle des réponses.
Ces sujets feront l’objet d’articles dédiés. Mais aucun ne compensera un index mal construit : c’est bien la phase amont, celle décrite ici, qui pose les fondations de tout ce qui vient après.