Alternatives / SUPABASE
Supabase vs Logiciel Sur-Mesure : quand le BaaS atteint ses limites
Supabase a convaincu des milliers d'équipes avec sa promesse d'un backend PostgreSQL prêt en quelques minutes. Mais quand votre application grandit, la logique métier s'accumule dans des Edge Functions difficiles à tester, les politiques RLS deviennent un labyrinthe de règles SQL, et la facture mensuelle devient imprévisible. Si votre équipe passe plus de temps à contourner les limites de Supabase qu'à livrer de la valeur, voici les questions à se poser.
SOYONS HONNÊTES
Ce que Supabase fait vraiment bien
Avant de parler limites, reconnaissons pourquoi Supabase vous a séduit à la base tout comme des millions d'utilisateurs.
- Démarrage ultra-rapide
- Base de données PostgreSQL, authentification, stockage et API prêts en quelques minutes. L'interface visuel permet de créer des tables et d'écrire du SQL sans infrastructure à configurer.
- PostgreSQL natif
- Accès direct à PostgreSQL avec toutes ses fonctionnalités : extensions, triggers, fonctions stockées, requêtes complexes. Pas de surcouche propriétaire sur la base de données.
- Authentification intégrée
- Gestion des utilisateurs, OAuth, magic links, MFA : tout est disponible sans configuration serveur. Idéal pour démarrer un MVP avec une authentification robuste en quelques heures.
- Open source
- Le code de Supabase est public. En théorie, vous pouvez l'auto-héberger. En pratique, la migration de l'infrastructure managée vers une instance propre reste une opération complexe.
- Realtime et subscriptions
- Écoutez les changements de la base de données en temps réel via WebSocket. Utile pour les tableaux de bord collaboratifs et les notifications instantanées.
Ces points forts restent valables. La question n'est pas "Supabase est-il bon ?" mais "Supabase est-il fait pour ce que vous en faites aujourd'hui ?"
LE PLAFOND DE VERRE
Pourquoi Supabase finit par freiner votre croissance
Ces limites ne sont pas des bugs. Supabase est un outil généraliste conçu pour s'adapter à toutes les situations, avec de nombreuses options de paramétrage.
C'est précisément ce qui en fait sa valeur, mais aussi ce qui vous transfère la charge de concevoir et de maintenir votre propre système dans le temps.
Logique métier éparpillée entre Edge Functions, triggers et RLS
Dans Supabase, la logique métier se répartit entre trois couches : les Edge Functions (Deno/TypeScript) pour les traitements côté serveur, les PostgreSQL Functions pour les calculs en base, et le Row Level Security (RLS) pour les règles d'accès. Cette dispersion rend la compréhension du système difficile : un comportement peut dépendre d'une politique RLS, d'un trigger PostgreSQL et d'une Edge Function appelée en cascade. Déboguer un bug métier dans ces conditions est chronophage.
Row Level Security : puissant mais fragile et invisible
RLS est une fonctionnalité PostgreSQL qui permet de restreindre les lignes visibles selon l'utilisateur. Supabase en fait la pierre angulaire de sa sécurité. Mais les politiques RLS sont écrites en SQL pur, sans framework de test ni de validation automatique. Une politique mal formulée expose silencieusement des données sensibles. Et comme ces règles vivent dans la base, elles ne sont pas versionées avec votre code applicatif sans outillage spécifique.
Coût imprévisible à l'usage
Supabase facture à la consommation : compute seconds pour les Edge Functions, stockage, bande passante, nombre de connexions actives. Un pic de trafic ou une requête mal optimisée peut faire exploser la facture du mois. Sur le plan Pro à 25$/mois, les dépassements s'ajoutent automatiquement, sans plafond par défaut. Pour une application métier en production, prévoir un budget mensuel stable est difficile.
Migration = réécriture quasi-complète
Si vous décidez de quitter Supabase, vous pouvez exporter votre base PostgreSQL via pg_dump : schéma, données, rôles, politiques RLS, triggers, fonctions et comptes utilisateurs (auth.users) sont inclus. Mais les Edge Functions, écrites pour le runtime Deno et incompatibles avec Node.js, doivent être téléchargées séparément et réécrites intégralement pour tout autre environnement. Les fichiers Supabase Storage nécessitent un script de migration dédié. Et toute la couche de configuration, JWT secrets, paramètres OAuth, SMTP et domaines personnalisés, doit être recréée manuellement. Le vendor lock-in ne porte pas sur les données, mais sur la logique applicative Deno et la configuration opérationnelle de la plateforme.
L'ALTERNATIVE SMARTBOOSTER
Un logiciel métier qui modélise votre réalité sans compromis
Remplacez Supabase par un logiciel sur mesure Symfony/Vue.js qui vous offre une vraie base relationnelle SQL, des droits d'accès granulaires et une logique métier illimitée, sans sacrifier l'ergonomie que vos équipes apprécient.
- Base de données relationnelle complète
- Clients, commandes, lignes, produits reliés avec des jointures SQL, sans limite de volume ni de structure.
- RBAC granulaire
- Droits par rôle, par équipe, par ligne de données : conformité RGPD native et confidentialité interne garantie.
- Automatisations métier réelles
- Calculs, règles conditionnelles complexes, déclencheurs horaires, intégrations API tierces sans limite.
- Hébergement Clever Cloud France
- Souveraineté totale sur vos données, SLA garanti, données hors CLOUD Act américain.
- Interface sur mesure
- UX conçue pour vos processus spécifiques, pas pour un usage générique : adoption rapide par vos équipes.
LA QUESTION IMPORTANTE
Avez-vous réellement besoin de quitter totalement Supabase ?
Chez SmartBooster, nous conseillons nos clients dans leur intérêt et ne reconstruisons pas ce qui fonctionne déjà. Si Supabase est en place dans votre entreprise, il reste certainement pertinent pour certains usages.
Nous commençons toujours par une cartographie de l'existant pour valider ce qui doit être migré et ce qui peut rester dans Supabase. Et souvent, la meilleure solution consiste à faire communiquer intelligemment les outils entre eux via des API.
COMPARATIF
Supabase vs Logiciel Sur-Mesure
Une comparaison objective pour vous aider à décider.
| Critère | Supabase | Sur-mesure SmartBooster |
|---|---|---|
| Propriété des données | Chez Supabase Inc. (AWS, région au choix) | 100% propriétaire, hébergé en France |
| Coût sur 3 ans | ~2 700€ min (plan Pro 25$/mois + compute variable) | Investissement unique, pas de facture récurrente par usage |
| Logique métier | Edge Functions (Deno), triggers SQL, politiques RLS : trois couches à maintenir | Services applicatifs Symfony : une seule couche, versionnée et testée |
| Droits d'accès | Row Level Security SQL : puissant mais fragile et non testé automatiquement | RBAC applicatif : rôles, équipes, lignes, champs, avec tests automatisés |
| Prévisibilité des coûts | Facturation à l'usage, dépassements automatiques | Coût fixe prévisible, pas de surprises en fin de mois |
| Portabilité | Données, RLS et triggers exportables via pg_dump, Edge Functions liées au runtime Deno | Code source livré, hébergement transférable |
| Couverture de tests | Politiques RLS non testables automatiquement sans outillage dédié | Tests automatisés sur chaque règle métier à chaque déploiement |
Comparaison technique : Supabase vs Logiciel Sur-Mesure
Schéma de données, logique métier, sécurité, authentification et API : comparaison point par point entre Supabase et un développement sur mesure Symfony.
Schéma de données et migrations
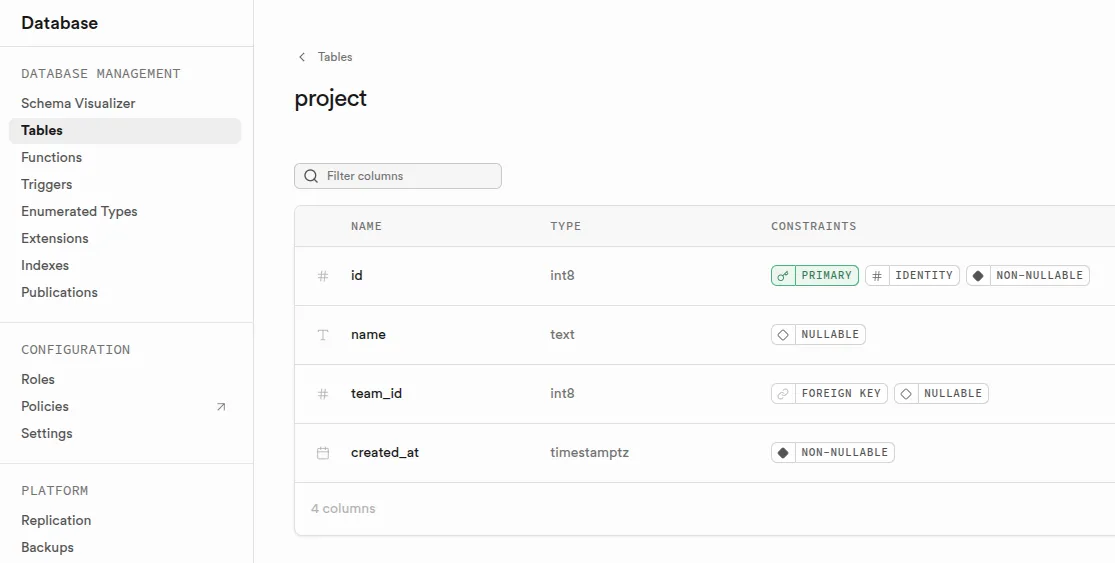
Supabase démarre vite parce que le schéma PostgreSQL se crée visuellement depuis l'inteface visuel Supabase Studio. Mais cette facilité a une contrepartie : sans discipline, le schéma de production évolue par modifications directes en interface, sans trace dans le code. Sur un projet Symfony, le schéma est généré depuis des entités PHP annotées, et chaque évolution est une migration Doctrine versionnée.
Modélisation du schéma
L'objectif est de définir tables, colonnes, relations et contraintes d'une manière qui reste lisible dans le code, traçable dans Git et reproductible sur n'importe quel environnement.
Supabase
Le schéma se crée principalement depuis le menu Database ou via le SQL Editor. Le CLI Supabase permet de capturer ces changements en fichiers de migration, mais cela suppose un workflow strict que l'interface graphique n'impose pas. En pratique, beaucoup d'équipes finissent avec un schéma de production qui n'est pas entièrement reflété dans le code source.
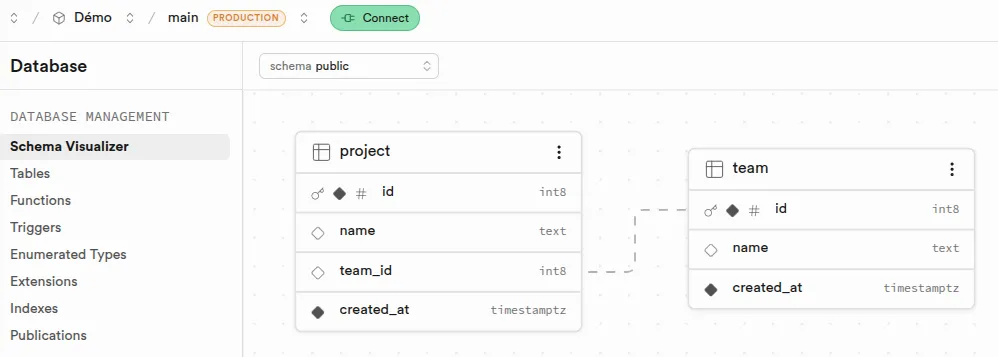
Définition d'une table via l'interface d'édition des colonnes d'une table :
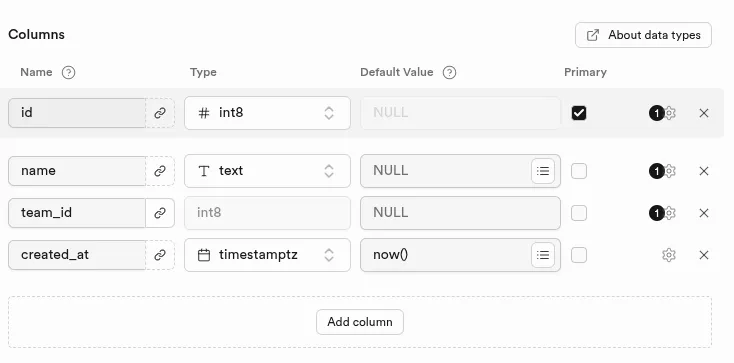
Détail de visualisation des colonnes d'une table :
Définition d'une table via le SQL Editor de Supabase :
sql
CREATE TABLE projects (
id bigint PRIMARY KEY DEFAULT gen_random_uuid(),
name text NOT NULL,
team_id bigint,
created_at timestamptz DEFAULT now()
);
ALTER TABLE "public"."project"
ADD CONSTRAINT "project_team_id_fkey"
FOREIGN KEY ("team_id")
REFERENCES "public"."team"("id")
ON DELETE SET NULL;
CREATE INDEX IF NOT EXISTS "project_team_id_idx" ON "public"."project" ("team_id");Interface supabase de visualisation des schémas :
Code sur mesure avec Doctrine
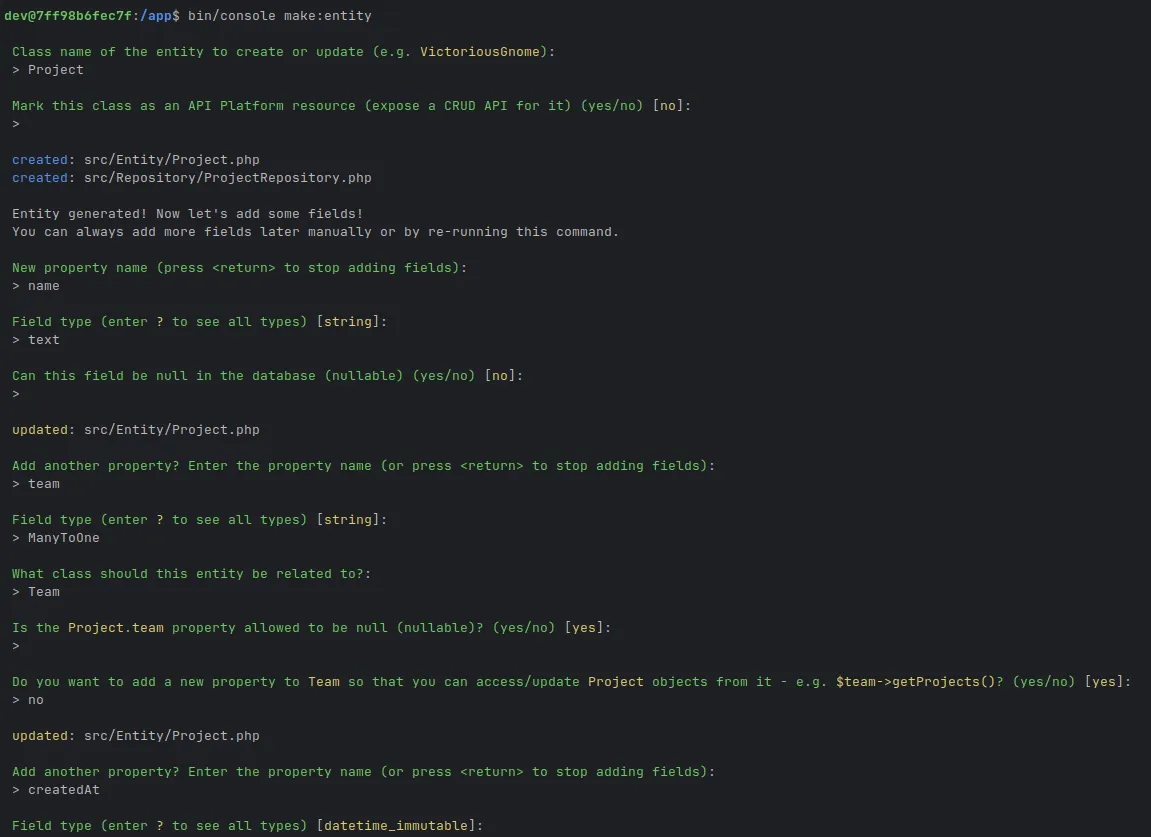
Le schéma est défini dans des entités Doctrine en PHP : chaque table correspond à une classe, chaque colonne à une propriété annotée. Les relations entre entités sont déclarées explicitement (OneToMany, ManyToOne, ManyToMany). MakerBundle de Symfony génère les entités depuis la ligne de commande, et Doctrine ORM produit ensuite le SQL adapté à la base cible.
Exemple d'intéraction avec l'utilitaire MakerBundle pour faciliter la création d'entité :
Code PHP de l'Entité Doctrine équivalente :
php
#[ORMEntity(repositoryClass: ProjectRepository::class)]
class Project
{
#[ORMId]
#[ORMGeneratedValue]
#[ORMColumn]
private ?int $id = null;
#[ORMColumn(type: Types::TEXT)]
private ?string $name = null;
#[ORMManyToOne]
private ?Team $team = null;
#[ORMColumn]
private ?DateTimeImmutable $createdAt = null;PHPStorm notre IDE de code nous permet aussi de visualiser le schéma d'une base de donnée :
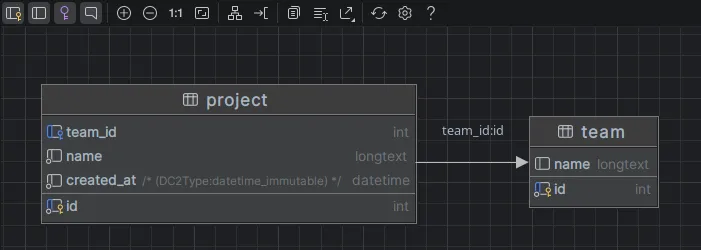
Versioning et déploiement
L'objectif est de pouvoir reproduire à l'identique le schéma de la production sur n'importe quel environnement (staging, recette, machine d'un nouveau développeur) et de pouvoir revenir en arrière si une migration introduit un problème.
Supabase
Le CLI Supabase propose supabase db diff pour capturer les changements et supabase migration new pour créer un fichier SQL versionné. Mais comme l'interface Supabase reste accessible, n'importe quel collaborateur peut modifier la production sans passer par le CLI : la divergence entre code source et schéma réel s'installe silencieusement, et la remise à niveau d'un environnement de développement devient un travail de reverse engineering.
Commandes CLI Supabase pour les migrations
bash
supabase db diff --schema public > supabase/migrations/20260512_new_deal.sql
supabase migration up
supabase db reset # remet à zéro l'environnement local
supabase link
supabase db push
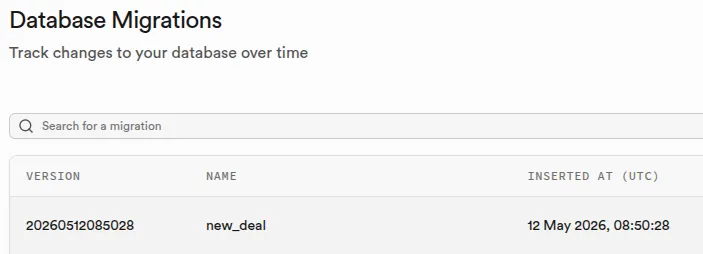
La notion de migration va de pair avec celle de branche : c'est ce couplage qui garantit que les changements de schéma arrivent en production exactement au moment où le code correspondant est fusionné sur main. Un changement de schéma sans fichier de migration commité restera invisible aux autres environnements. Supabase Branching est disponible sur les plans payants et nécessite l'intégration GitHub configurée sur le projet.
Doctrine Migrations
Doctrine Migrations génère un fichier PHP horodaté à chaque changement d'entité, avec une méthode up() et une méthode down() pour le rollback. Les migrations sont rejouées dans l'ordre sur chaque environnement et exécutées en CI/CD à chaque déploiement. La production ne peut pas diverger du code : il n'existe pas d'interface graphique qui permet de modifier le schéma en dehors du flux de versioning.
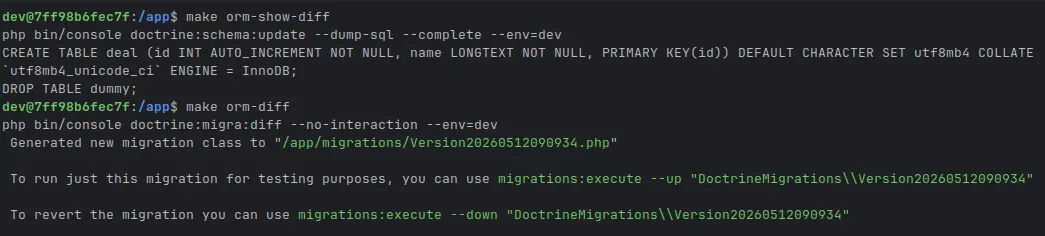
Migration Doctrine versionnée
php
final class Version20260512090934 extends AbstractMigration
{
public function getDescription(): string
{
return 'Ajout de la table deal (opportunité)';
}
public function up(Schema $schema): void
{
$this->addSql('CREATE TABLE deal (id INT AUTO_INCREMENT NOT NULL, name LONGTEXT NOT NULL, PRIMARY KEY(id)) DEFAULT CHARACTER SET utf8mb4 ENGINE = InnoDB');
$this->addSql('DROP TABLE dummy');
}
public function down(Schema $schema): void
{
$this->addSql('CREATE TABLE dummy (id INT AUTO_INCREMENT NOT NULL, foo VARCHAR(255) CHARACTER SET utf8mb4 NOT NULL, bar VARCHAR(255) CHARACTER SET utf8mb4 NOT NULL , PRIMARY KEY(id)) DEFAULT CHARACTER SET utf8mb4 ENGINE = InnoDB COMMENT = '' ');
$this->addSql('DROP TABLE deal');
}
}Architecture de la logique métier
Dans Supabase, une même fonctionnalité peut être implémentée à trois endroits : Edge Functions en Deno, fonctions et triggers PostgreSQL, politiques RLS. Cette dispersion accélère les premiers développements mais complexifie chaque évolution. Sur un logiciel Symfony, la logique vit dans une seule couche de code, lisible et testable de bout en bout.
Où vit la logique métier
L'objectif est de pouvoir comprendre, modifier ou auditer une règle métier sans avoir à parcourir plusieurs systèmes techniques. Plus la logique est dispersée, plus le coût de chaque évolution augmente.
Supabase
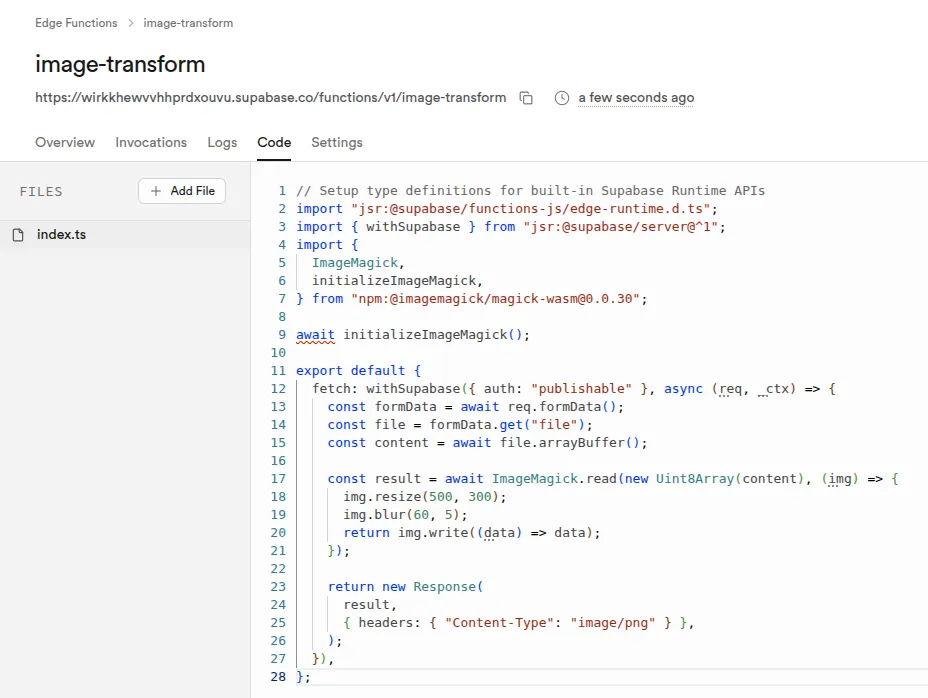
Une fonctionnalité peut être implémentée dans trois endroits différents : une Edge Function exécutée par le runtime Deno, un trigger PostgreSQL en PL/pgSQL, et une politique RLS en SQL pur. Comprendre ce qui se passe lors d'un simple INSERT impose de regarder les trois couches en parallèle.
Exemple d'Edge Function en Deno/TypeScript
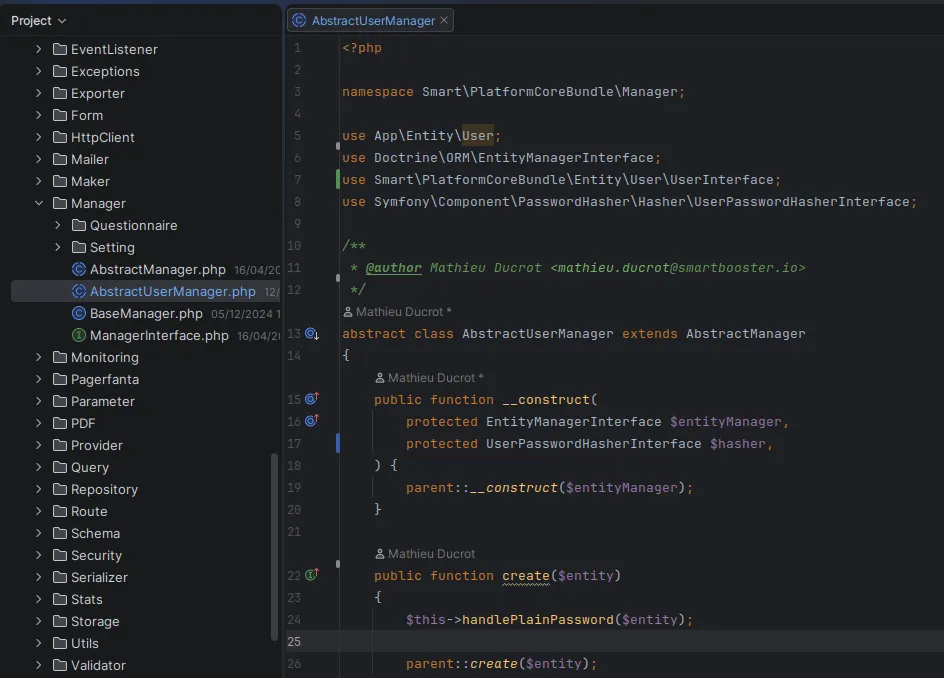
Arborescence des services dans Symfony
La logique métier vit dans des services Symfony, une seule couche de code PHP versionnée dans Git et exécutée dans le même processus que les contrôleurs HTTP. Pas de runtime Deno parallèle, pas de SQL dispersé dans la base. Un développeur ouvre une seule classe pour comprendre une fonctionnalité.
Exemple d'arborescence des services dans notre SmartPlatform et exemple de Manager
Tests automatisés et débogage
L'objectif est d'avoir un filet de sécurité automatisé qui détecte les régressions avant la production, et de pouvoir tracer un bug jusqu'à sa source en quelques minutes plutôt qu'en quelques heures.
Supabase
Les Edge Functions peuvent être testées avec Deno, mais les triggers PostgreSQL et les politiques RLS n'ont pas de framework de test natif. Un bug peut provenir d'un trigger qui modifie une ligne en cascade ou d'une politique RLS qui filtre silencieusement le résultat : le débogage impose de jongler entre les logs Edge Functions, le SQL Editor et la console Postgres.
Politique RLS livrée sans test associé
PHPUnit
Chaque règle métier est couverte par PHPUnit : tests unitaires sur les services, tests fonctionnels sur les contrôleurs, tests d'intégration sur les requêtes Doctrine. Le Symfony Profiler trace chaque requête HTTP avec les requêtes SQL, les services appelés et les exceptions. Une régression détectée en CI bloque le merge avant la mise en production.
Exemple de test et couverture de code analysé sur nos projets avec PHPUnit qui tourne sur nos CI Gitlab.
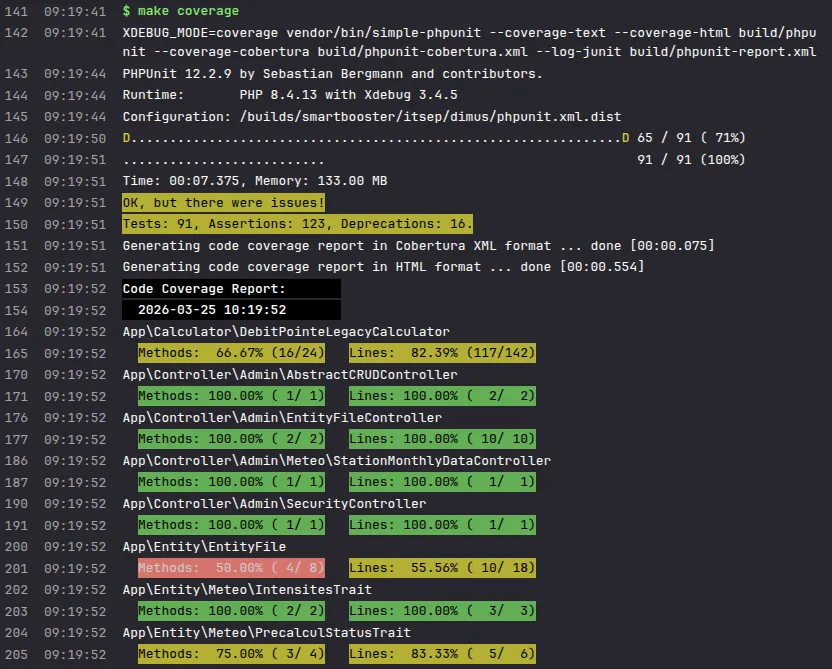
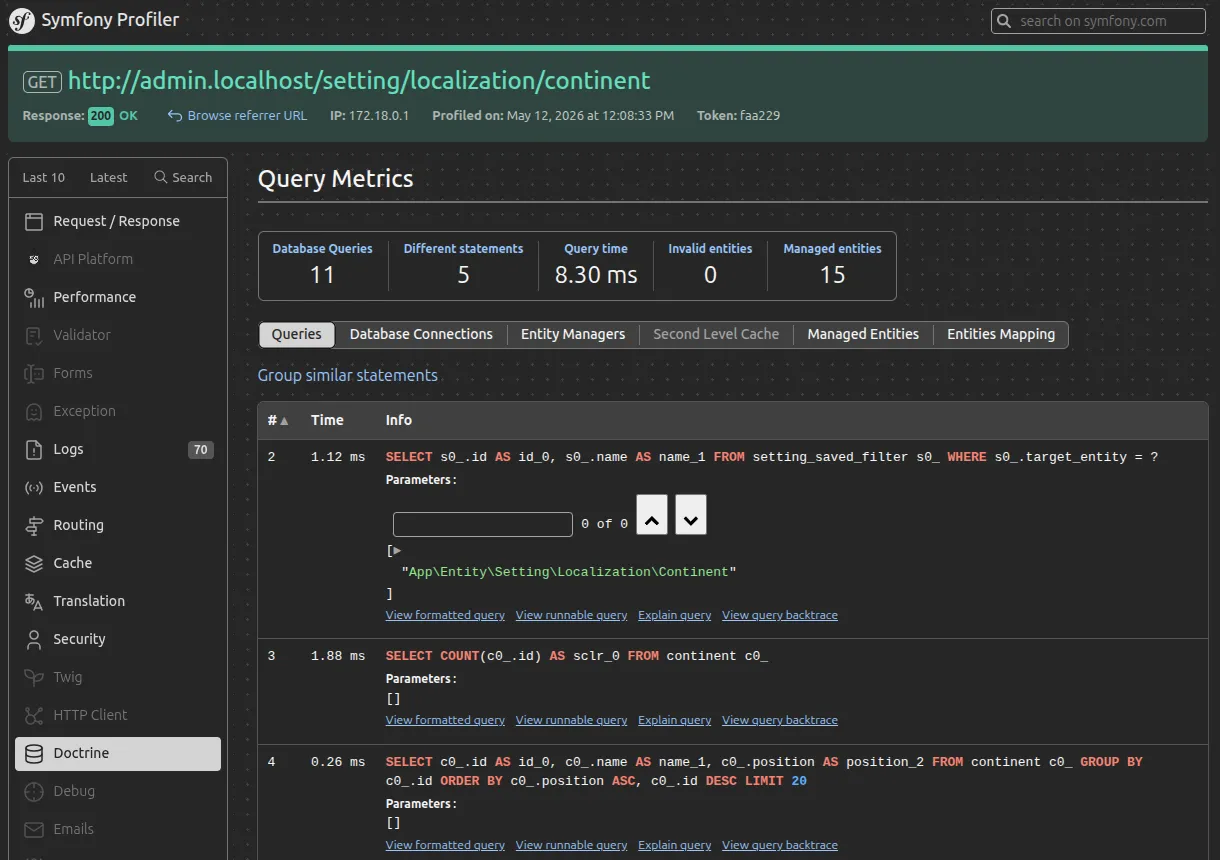
Écran Symfony Profiler pour analyser les requêtes effectué par Doctrine
Sécurité et droits d'accès
Le Row Level Security est la pierre angulaire de la sécurité Supabase : chaque table doit être protégée par des politiques SQL qui filtrent les lignes selon l'utilisateur connecté. C'est puissant, mais le contrôle vit dans la base de données, sans framework de test ni versioning natif. Sur un projet Symfony, les droits sont du code applicatif testable et versionné comme le reste.
Définition des règles d'accès
L'objectif est de définir qui voit quoi, qui peut modifier quoi, et de pouvoir auditer ces règles sans ouvrir un éditeur SQL. Plus les règles sont proches du code applicatif, plus elles sont faciles à faire évoluer.
Supabase
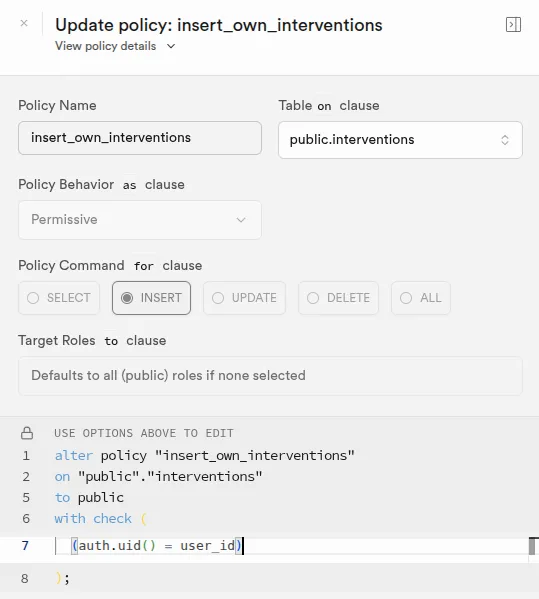
Les règles sont des politiques RLS écrites en PostgreSQL pur, attachées à chaque table. Une fois enable_row_level_security activé, toute requête est filtrée par la politique. Le SQL est expressif, mais ces règles vivent dans la base et ne sont pas versionnées avec le code applicatif sans outillage spécifique. Une politique mal écrite expose silencieusement des données : pas d'erreur, juste des lignes en moins ou en trop.
Interface d'édition d'une politique RLS dans Supabase
Composant Sécurité natif de Symfony
Les droits sont définis dans des Security Voters Symfony : des classes PHP qui répondent à "Est-ce que cet utilisateur peut faire cette action sur cette ressource". Le voter est appelé explicitement dans le contrôleur ou via un attribut, et chaque scénario peut être testé. Le code des droits est versionné dans Git au même titre que le reste du logiciel.
Voter Symfony pour l'accès à un projet
php
final class ProjectVoter extends Voter
{
protected function voteOnAttribute(string $attr, $project, TokenInterface $token): bool
{
$user = $token->getUser();
return $project->getTeam()->hasMember($user);
}
}Exemple de test d'un voter Symfony
php
class ProjectVoterTest extends TestCase
{
public function testMemberCanViewProject(): void
{
$user = new User();
$team = (new Team())->addMember($user);
$project = new Project($team);
$token = new UsernamePasswordToken($user, 'main', []);
$this->assertSame(
VoterInterface::ACCESS_GRANTED,
(new ProjectVoter())->vote($token, $project, ['VIEW'])
);
}
public function testNonMemberIsRefused(): void
{
$outsider = new User();
$project = new Project(new Team());
$token = new UsernamePasswordToken($outsider, 'main', []);
$this->assertSame(
VoterInterface::ACCESS_DENIED,
(new ProjectVoter())->vote($token, $project, ['VIEW'])
);
}
}Granularité des droits
L'objectif est de restreindre l'accès non seulement aux lignes d'une table, mais aussi à certains champs et à certaines actions selon le contexte métier (statut d'un dossier, rôle dans une équipe, périmètre d'un manager).
Supabase
RLS travaille naturellement au niveau ligne. Restreindre l'accès à certaines colonnes impose de créer des vues PostgreSQL dédiées ou de multiplier les politiques par opération (SELECT, INSERT, UPDATE, DELETE). Pour des règles qui dépendent du statut d'une entité, du rôle dans une équipe et d'une période, les politiques deviennent rapidement difficiles à relire et à maintenir.
Empilement de politiques par opération
sql
CREATE POLICY "read_own_team" ON projects FOR SELECT USING (...);
CREATE POLICY "read_archived_if_admin" ON projects FOR SELECT USING (...);
CREATE POLICY "insert_if_team_member" ON projects FOR INSERT WITH CHECK (...);
CREATE POLICY "update_if_manager" ON projects FOR UPDATE USING (...);
CREATE POLICY "update_status_if_owner" ON projects FOR UPDATE USING (...);
CREATE POLICY "delete_if_admin" ON projects FOR DELETE USING (...);RBAC sur mesure
Le système de droits est un RBAC (Role-Based Access Control) complet : rôles, équipes, lignes, champs et actions. Notre SmartPlatform fournit un socle de gestion des profils utilisateurs avec un contrôle granulaire sur chaque fonctionnalité et chaque donnée. Les règles métier sont exprimées en PHP avec accès au contexte applicatif complet, et chaque scénario est couvert par un test fonctionnel.
Exemple de hierarchisation des accès via le role_hierarchy du composant Security de Symfony
yaml
role_hierarchy:
ROLE_PROFILE_ADMINISTRATOR:
- ROLE_SUPER_ADMIN
- ROLE_SETTING_USER_ADMINISTRATOR_IMPERSONATE
- ROLE_MONITORING
ROLE_PROFILE_USER_BEGINNER:
- ROLE_CRM_ORGANIZATION_LIST
- ROLE_CRM_CONTACT_LIST
- ROLE_CRM_DEAL_LIST
ROLE_PROFILE_USER_EXPERT:
- ROLE_CRM_ORGANIZATION_LIST
- ROLE_CRM_ORGANIZATION_DOWNLOAD_FILE
- ROLE_CRM_ORGANIZATION_UPDATE_CRM
- ROLE_CRM_CONTACT_LIST
- ROLE_CRM_CONTACT_UPDATE
- ROLE_CRM_DEAL_ALL
ROLE_PROFILE_USER_MANAGER:
- ROLE_CRM_ORGANIZATION_ALL
- ROLE_CRM_CONTACT_LIST
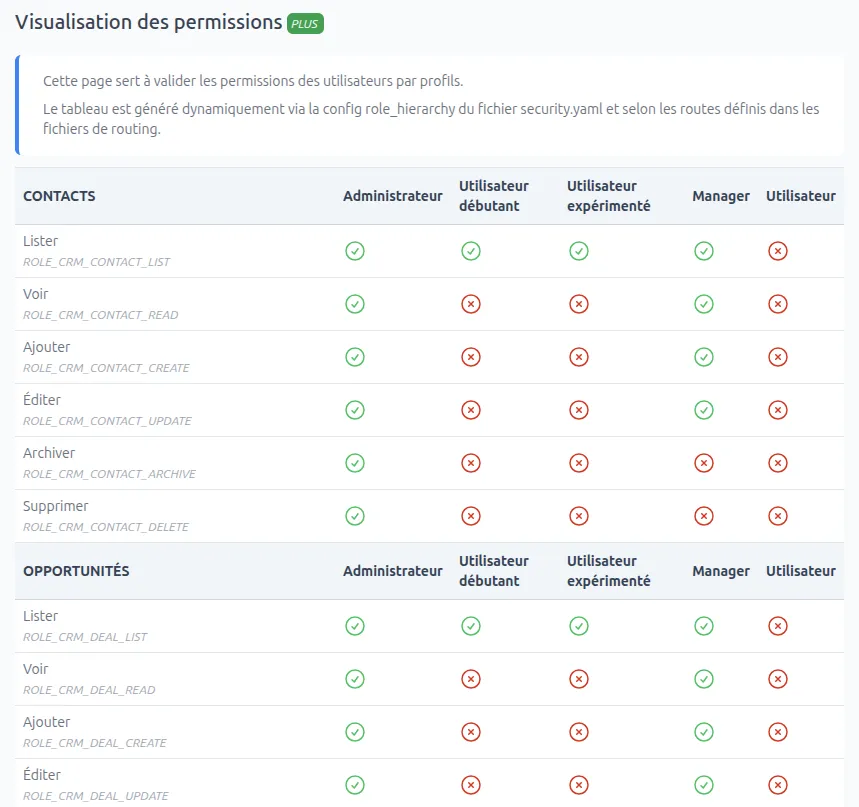
- ROLE_CRM_DEAL_ALLAvec un développment sur mesure comme avec notre SmartPlatform il devient très facile de visualiser chacun des accès des profils à leur ressources, le tout dynamiquement en se basant sur notre code.
Authentification et stockage
Les briques transverses de Supabase (Authentication et Supabase Storage pour les fichiers) sont rapides à activer mais difficiles à étendre dès qu'on s'écarte du chemin standard. Un développement sur mesure remplace ces briques par des composants Symfony que vos équipes maîtrisent entièrement et adaptent à votre contexte métier.
Authentification et gestion des utilisateurs
L'objectif est de proposer une connexion fiable, des règles de mot de passe conformes à votre politique de sécurité, et une intégration des comptes avec votre système d'information existant si nécessaire.
Supabase
L'authentification repose sur GoTrue : email/password, magic links, OAuth et MFA disponibles sans configuration serveur. Les comptes vivent dans la table auth.users, séparée de votre schéma applicatif. Étendre le modèle utilisateur impose de créer une table profiles reliée à auth.users : chaque requête doit joindre les deux tables pour disposer du contexte complet.
Connexion d'un utilisateur via le client Supabase
typescript
const { data, error } = await supabase.auth.signInWithPassword({
email: 'user@example.com',
password: 'secret',
})
const { data: profile } = await supabase
.from('profiles')
.select('*')
.eq('id', data.user.id)
.single()Écran de configuration Supabase des providers d'authentification
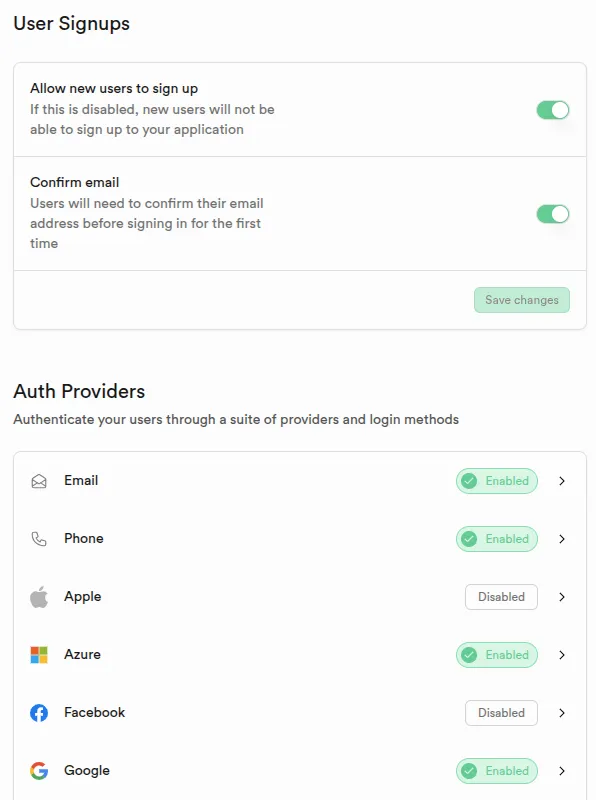
Code sur mesure
Symfony Security gère l'authentification via des Authenticators et UserProviders configurables. L'entité User vit dans votre schéma applicatif avec tous ses champs métier (équipe, rôle, préférences, périmètre) déclarés au même endroit.Nous ne réinventons pas la roue, notre SmartPlatform fournit un écran de connexion soigné, la récupération de mot de passe et des règles conformes aux recommandations ANSSI sans développement supplémentaire.
Entité User unifiée avec les champs métier
php
#[ORM\Entity]
class User implements UserInterface, PasswordAuthenticatedUserInterface
{
#[ORM\Column(unique: true)]
private string $email;
#[ORM\Column]
private string $password;
#[ORM\ManyToOne(targetEntity: Team::class)]
private Team $team;
#[ORM\Column(type: 'json')]
private array $roles = ['ROLE_USER'];
}Exemple de rendu d'écran de login
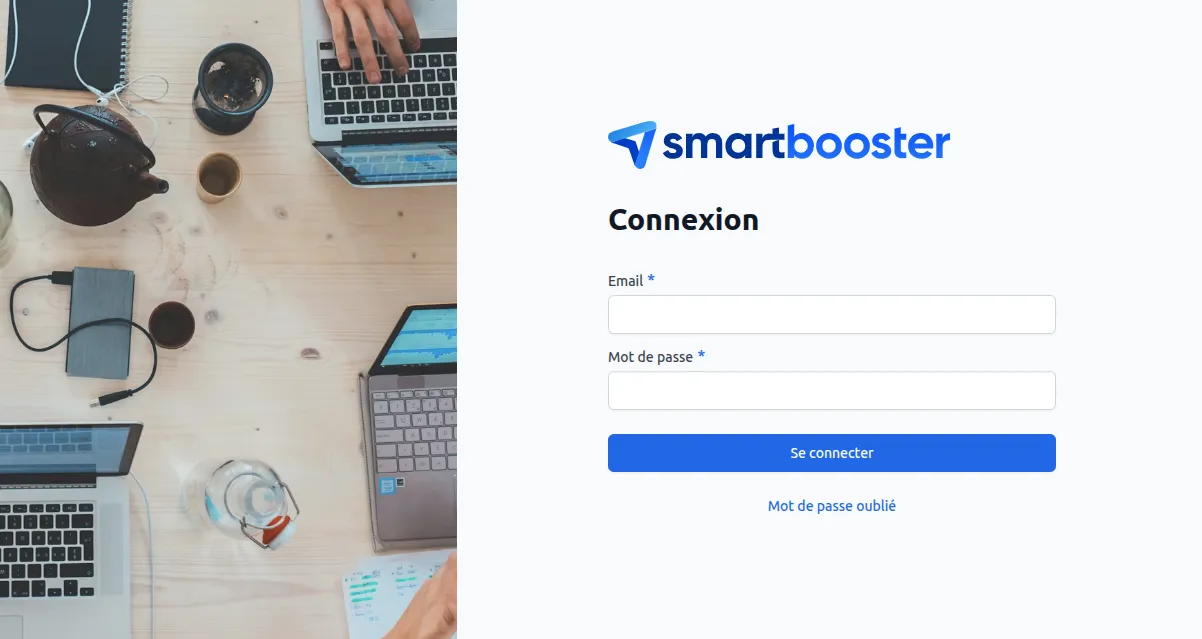
Chaque interface peut avoir son propre écran de connexion : charte graphique, logo, couleurs et wording adaptés à l'audience. Un extranet client, un espace partenaire et un back-office interne peuvent coexister dans le même logiciel avec des identités visuelles distinctes, sans multiplier les projets ni les bases de code.
Comme Supabase, nous intégrons les connexions via les grandes plateformes sociales et professionnelles : Google, Microsoft, LinkedIn, GitHub ou tout fournisseur OAuth 2.0 compatible.
Stockage et accès aux fichiers
L'objectif est de stocker des fichiers (documents, images, PDF générés) avec un contrôle d'accès aligné sur les règles métier du logiciel, et de pouvoir migrer le stockage si l'hébergement change.
Supabase
Supabase Storage expose des buckets S3-compatibles avec des politiques RLS écrites en SQL pour contrôler l'accès aux objets. Les fichiers sont stockés sur l'infrastructure Supabase : migrer vers un autre fournisseur impose un script de copie objet par objet. Les politiques d'accès vivent encore une fois en SQL pur, séparées de la logique applicative qui décide quand un fichier est lisible.
Écran de configuration Supabase des policies sur les bucket des fichiers :
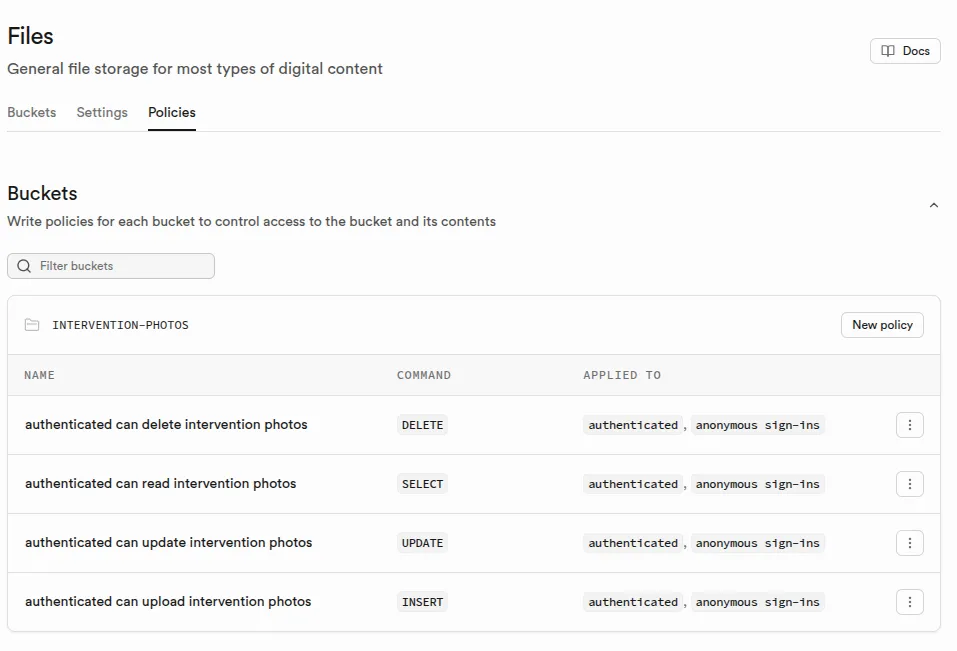
Code sur mesure
Le stockage passe par Flysystem, l'abstraction Symfony qui s'adapte à n'importe quel fournisseur : système de fichiers local, S3, Scaleway Object Storage, OVH ou Clever Cloud Cellar. Le contrôle d'accès est géré côté contrôleur via le RBAC de l'application. Changer d'hébergement de stockage ne demande qu'une mise à jour de configuration.
Exemple de configuration Flysystem mixant fournisseur S3 et local storage via FSBucket
yaml
flysystem:
storages:
local.calculation_file:
adapter: 'local'
directory_visibility: public
options:
directory: '%app.public_dir%%app.files.calculation_file_prefix%'
aws.entity_file:
adapter: 'aws'
options:
client: 'AwsS3S3Client'
bucket: '%env(CELLAR_ADDON_BUCKET_FILES_NAME)%'
prefix: '%app.files.entity_file_prefix%'
Fonctionnalités avancées
Supabase va plus loin qu'une simple base de données : il expose automatiquement une API REST sur vos tables et permet de planifier des tâches récurrentes directement depuis la base. Ces fonctionnalités accélèrent les premiers développements, mais elles reposent sur des composants open source que l'on peut aussi configurer sur un projet sur mesure selon les mêmes principes.
API REST auto-générée
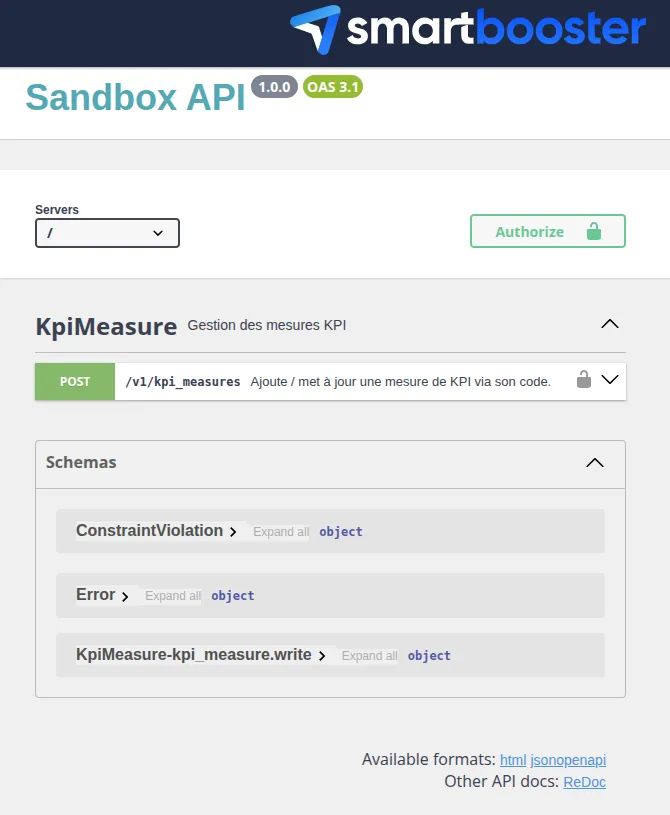
L'objectif est d'exposer des endpoints REST sur les données sans écrire de contrôleurs à la main, avec un contrat d'API documenté et une gestion des droits cohérente avec le reste du logiciel.
Supabase
Supabase expose automatiquement une Data API REST sur chaque table et vue de votre base, alimentée en interne par PostgREST. Chaque table devient un endpoint : GET pour lire, POST pour insérer, PATCH pour mettre à jour, DELETE pour supprimer. Les politiques RLS filtrent les résultats selon l'utilisateur connecté. L'API est disponible à /rest/v1/. Supabase propose un explorateur par table listant les champs disponibles, mais ne génère pas de documentation au format OpenAPI.
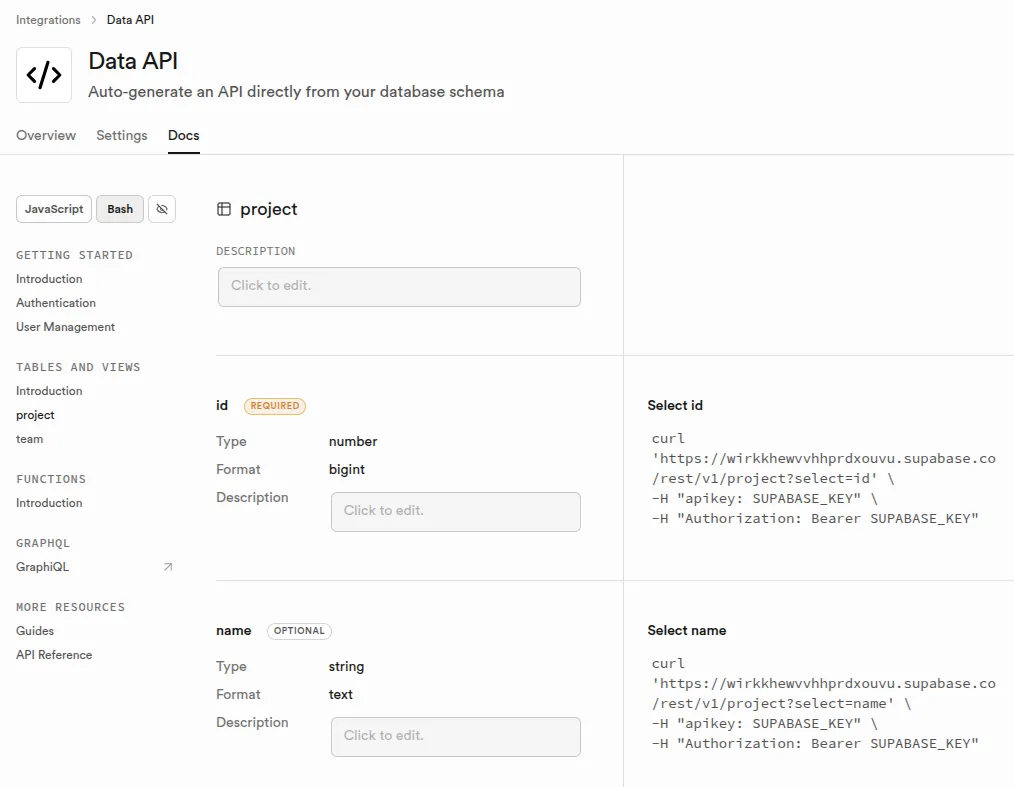
Exemple de requête Data API Supabase via le client JS
typescript
const { data, error } = await supabase
.from('projects')
.select('id, name, team_id')
.eq('status', 'active')
.order('created_at', { ascending: false })Code sur mesure
Sur un projet avec une base PostgreSQL, on peut configurer PostgREST de la même façon pour exposer une Data API identique à celle de Supabase, sans passer par la plateforme. En parallèle, API Platform permet d'obtenir le même résultat depuis les entités Doctrine : les endpoints REST (et GraphQL si besoin) sont générés depuis les classes PHP annotées, avec pagination, filtres, validation et documentation OpenAPI inclus. Les droits d'accès sont gérés par les voters Symfony, au même endroit que le reste de la logique métier.
Exposition d'une ressource via API Platform
php
#[ApiResource(
operations: [
new GetCollection(),
new Get(),
new Post(),
new Patch(),
],
normalizationContext: ['groups' => ['project:read']],
)]
#[ORM\Entity]
class Project
{
#[ORM\Id, ORM\GeneratedValue, ORM\Column]
#[Groups(['project:read'])]
private ?int $id = null;
#[ORM\Column(type: Types::TEXT)]
#[Groups(['project:read'])]
private string $name;
}
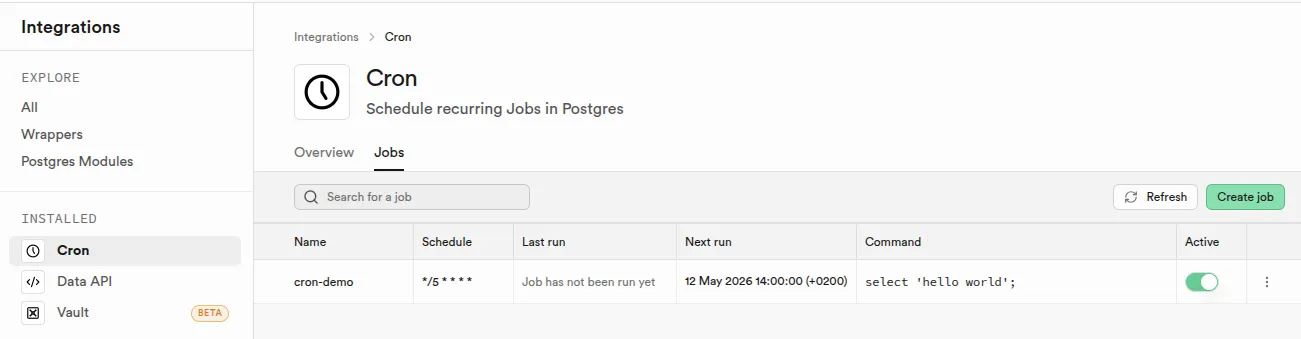
Tâches planifiées (cron)
L'objectif est de déclencher automatiquement des traitements récurrents : nettoyage de données, envoi de rapports, synchronisations périodiques, sans dépendre d'un déclencheur externe.
Supabase
Supabase Cron s'appuie sur l'extension pg_cron de PostgreSQL pour planifier des jobs directement depuis la base. Chaque job est une requête SQL ou un appel à une Edge Function, configuré avec une expression cron standard. Les jobs sont visibles dans le Supabase et leurs historiques d'exécution sont consultables depuis l'interface.
Planification d'un job de nettoyage hebdomadaire via Supabase Cron
sql
select cron.schedule(
'saturday-cleanup', -- nom du job
'30 3 * * 6', -- samedi à 3h30 (GMT)
$$ delete from events where event_time < now() - interval '1 week' $$
);
Code sur mesure
Les tâches planifiées sont des commandes Symfony déclenchées par un cron système configuré sur le serveur. Chaque tâche est une classe PHP versionnée dans Git, testable unitairement et tracée dans les logs applicatifs. L'ajout ou la modification d'un job passe par une pull request comme n'importe quelle évolution du logiciel.
Commande Symfony déclenchée par cron
php
#[AsCommand(name: 'app:events:cleanup')]
final class CleanupEventsCommand extends Command
{
public function __construct(private EventRepository $events) {}
protected function execute(InputInterface $input, OutputInterface $output): int
{
$count = $this->events->deleteOlderThan(new \DateTimeImmutable('-1 week'));
$output->writeln("$count événements supprimés.");
return Command::SUCCESS;
}
}Exemples d'utilisation
Ce que nous pouvons construire !
En fonction de vos priorités, nous pouvons utiliser des composants préexistants pour gagner du temps sur les parties non-essentielles et aller jusqu'au 100% sur mesure pour les parties critiques de votre projet.
Interface de gestion & Administration
Pilotez vos données internes avec une interface d'administration sécurisée, conçue pour centraliser vos processus métier complexes.
CRM & Gestion Commerciale
Centralisez vos prospects, automatisez vos tunnels de vente et boostez votre conversion avec un CRM sur mesure adapté à votre cycle de vente.
Création de Plateforme SaaS
Lancez votre produit logiciel sur une base scalable : gestion multi-tenant, abonnements, RBAC et infrastructure haute disponibilité.
Reporting & Business Intelligence
Visualisez vos KPIs en temps réel avec des tableaux de bord interactifs : génération de rapports PDF, alertes et suivi d'objectifs.
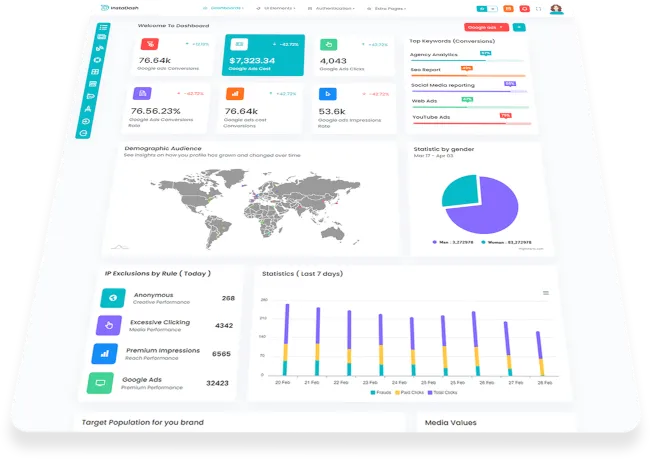
Gestion de Tâches & Suivi d'Activité
Planifiez, assignez et suivez les tâches de vos équipes avec un outil adapté à vos processus : kanban, checklists, workflows et alertes.
Outils internes sur mesure
Du calculateur métier à la plateforme multi-profil : structurez votre savoir-faire et automatisez vos processus avec un outil conçu pour votre façon de travailler.
Logiciel métier sur mesure
Modélisez vos processus dans un logiciel multi-profil qui centralise vos opérations et transforme votre savoir-faire en actif stratégique durable.
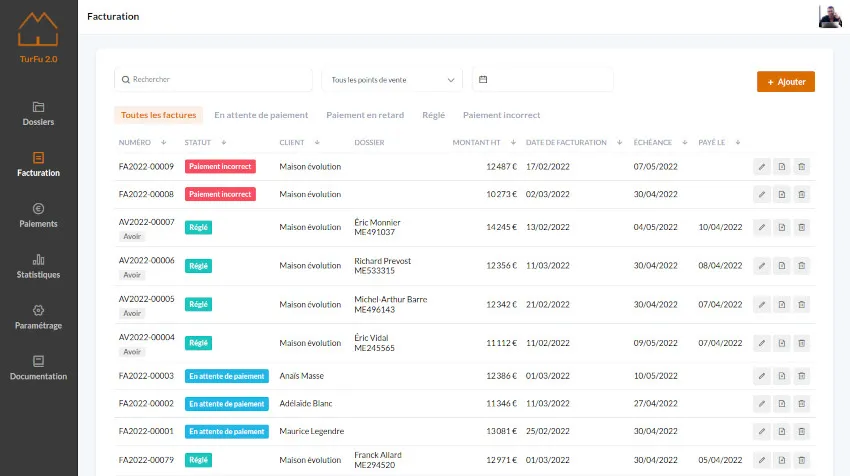
Gestion de Processus Métier
Modélisez vos circuits de validation, automatisez vos relances et centralisez le suivi de vos dossiers dans un logiciel adapté à vos processus réels.
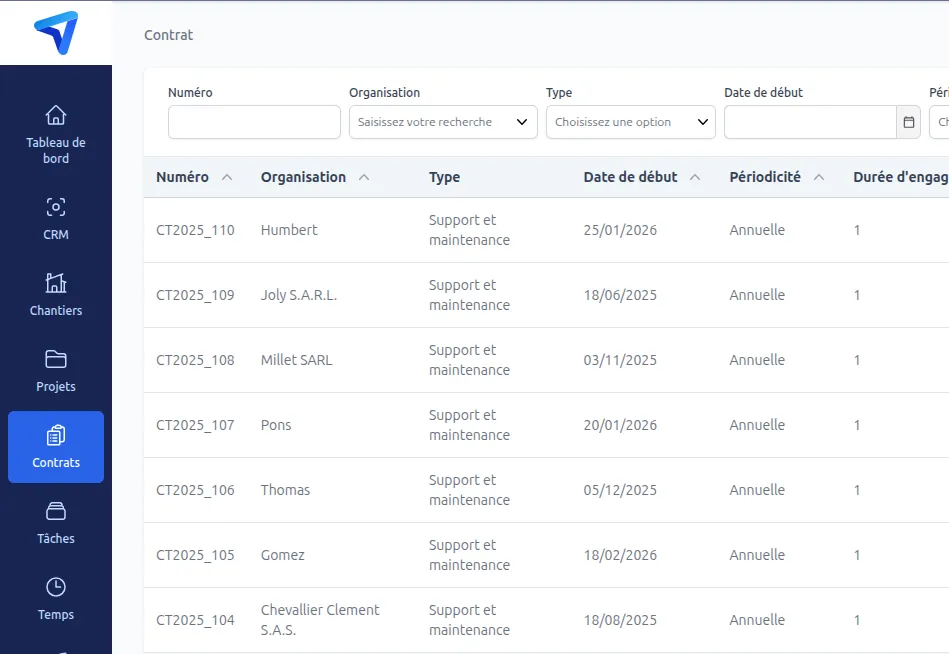
SAV & Gestion des interventions
Portail client de dépôt, workflow de traitement adapté à votre cycle, notifications automatiques et connexion ERP : un logiciel SAV calqué sur vos processus réels.
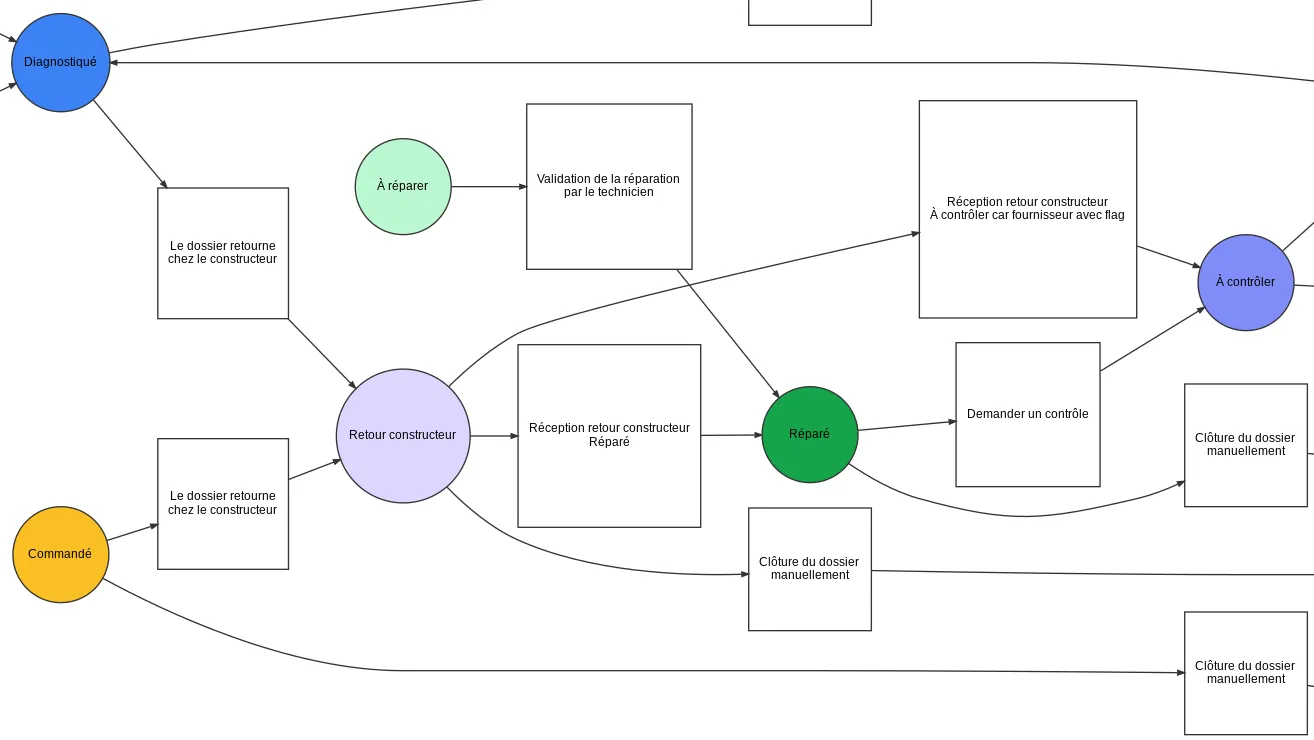
Logiciel de Diagnostic & Audit
Automatisez vos expertises : questionnaires intelligents, calcul de scores métier et génération instantanée de rapports PDF.
Simulateur et calculateur métier sur mesure
Concrétisez vos arguments commerciaux avec un outil interactif : questionnaire dynamique, calcul en temps réel et résultats personnalisés selon les réponses du visiteur.
Outil de chiffrage sur mesure
Centralisez vos grilles de prix, guidez la saisie et générez des devis précis en quelques minutes : plus d'erreurs de formule, plus d'écarts entre commerciaux.
RENDEZ-VOUS DÉCOUVERTE GRATUIT
Votre usage de Supabase vous freine-t-il ?
En 30 minutes d'échange, nous analysons votre situation et vous disons honnêtement si un logiciel sur mesure vous apporterait une valeur réelle.
Appel de 30 min → Analyse gratuite → Proposition sous 5 jours

LA MIGRATION
Migrer depuis Supabase sans perdre vos données ni votre logique
Supabase permet un export PostgreSQL complet. Nous analysons votre schéma, remappons les Edge Functions en services applicatifs Symfony, et convertissons les politiques RLS en un système de droits versionnable et couvert par des tests. Vos équipes continuent à travailler sur Supabase pendant le développement.
Étape 1 : Analyse
Cartographie de ce qui existe dans Supabase
Avant de migrer quoi que ce soit, nous analysons l'ensemble de votre usage de Supabase : bases de données, relations entre entités, automatisations en place, volumes de données.
Nous identifions précisément ce qui doit migrer vers le logiciel sur mesure et ce qui peut rester dans Supabase. Cet état des lieux dessine une vision claire de votre façon de travailler : ce que nous devons conserver, améliorer, supprimer et créer dans votre nouveau logiciel.
Pour comprendre comment vos données sont organisées dans Supabase avant la migration : documentation officielle Supabase
Audit des bases et relations
Inventaire de toutes vos bases, propriétés, relations et vues dans Supabase pour établir une carte complète de vos données.
Décision sur ce qui migre
Concertation sur ce qui passe dans le logiciel et ce qui reste dans Supabase, pour ne reconstruire que ce qui apporte une vraie valeur.
Plan de migration validé
Document structuré avec priorités, format cible et estimation. Vous validez avant de démarrer.
Étape 2 : Migration
Import contrôlé de votre historique
Supabase propose un export de vos données. Nous analysons la structure exportée, reconstituons les relations entre entités et importons l'historique dans la nouvelle base SQL.
Chaque import est contrôlé : les données mal formées sont signalées avant injection, pas après. Votre historique arrive sans perte ni approximation. Selon votre contexte, nous pouvons réaliser l'import directement ou vous construire des écrans d'import sur mesure : vous gardez ainsi la main pour trier, corriger et ajuster vos données avant injection, ce que Supabase ne permet pas toujours de faire avec la précision nécessaire.
Ce que nous migrons
- Base de données PostgreSQL : dump SQL complet avec tables, index, relations et données
- Schéma et migrations : historique des migrations Supabase remappé en migrations Doctrine
- Authentification et utilisateurs : comptes, rôles et droits recréés dans le nouveau système
- Fichiers stockés (Supabase Storage) : assets migrés vers le stockage cible
- Edge Functions : logique réécrite en services Symfony avec couverture de tests
- Politiques RLS : règles d'accès converties en RBAC applicatif versionnable et testable
Export et analyse
Export complet depuis Supabase, analyse de la structure et mapping vers le modèle de données cible du logiciel sur mesure.
Import avec validation
Contrôle qualité avant injection : doublons, relations manquantes et données incomplètes sont signalés avant tout enregistrement.
Migration progressive si besoin
Cohabitation possible entre les deux systèmes pendant la transition : vous basculez fonctionnalité par fonctionnalité.
Étape 3 : Bascule
Transition en parallèle, sans rupture de service
Le logiciel sur mesure est développé pendant que vous continuez à travailler dans Supabase. Vos équipes basculent quand elles sont prêtes, à leur rythme.
Pas de date butoir imposée : vous gardez le contrôle du calendrier et décidez du moment où chaque module entre en production.
Nous déployons les fonctionnalités au fur et à mesure qu'elles sont prêtes, ce qui permet une migration et une amélioration progressives. Vos équipes se forment sur le terrain, et leurs retours alimentent directement les ajustements des modules suivants.
Développement en parallèle
Le logiciel est construit pendant que votre équipe continue sur Supabase, sans interruption d'activité.
Formation progressive
Prise en main accompagnée, aide contextuelle intégrée dans le logiciel, montée en compétence sans stress.
Bascule à votre rythme
Vous décidez du moment de la bascule complète. Pas de date imposée, pas de rupture opérationnelle.
Nos engagements
Ce que vous pouvez exiger de nous
Propriété totale du code source
Vous êtes pleinement propriétaire du code que nous développons pour vous et pouvez maîtrisez son évolution.
Développement 100 % en France
Équipe est basée en France, communication simplifié sans décalage horaire pour une bonne compréhension.
Hébergement cloud souverain
Déploiement sur une infrastructure française avec support réactif. Vos données restent en France.
Pour aller plus loin
Approfondir votre réflexion
De la conception au déploiement, découvrez comment nous développons des logiciels métier qui s'adaptent à vos processus, pas l'inverse.
Avant de migrer complètement, un prototype vous permet de valider vos choix fonctionnels avec vos équipes, à moindre coût.
FAQ
Les réponses à vos questions
Et si vous ne trouvez pas ce que vous cherchez, nous serons ravis de vous répondre en direct lors d'un rendez-vous entre humains !
Oui. Supabase exporte via pg_dump votre schéma complet, vos données, vos rôles, vos politiques RLS, vos triggers et les comptes utilisateurs (auth.users). Les Edge Functions (runtime Deno) doivent être téléchargées séparément et réécrites pour un autre environnement. Les fichiers Supabase Storage nécessitent un script de migration dédié. Aucune donnée métier n'est perdue, mais la logique applicative Deno ne se porte pas directement vers un autre runtime.
Nous développons le nouveau logiciel en parallèle pendant que votre application continue de fonctionner sur Supabase. La bascule se fait fonctionnalité par fonctionnalité, avec une période de cohabitation si nécessaire. Pas de date butoir imposée, pas de rupture de service.
Oui. Supabase reste pertinent comme base de données pour des besoins spécifiques (realtime, auth rapide sur un module). Nous pouvons développer uniquement les modules critiques (logique métier complexe, reporting, RBAC avancé) et les connecter à Supabase via API pour éviter une migration totale.
Un premier module est généralement livrable en 4 à 8 semaines. Le délai dépend de la complexité des Edge Functions à réécrire, du nombre de politiques RLS à convertir et des volumes de données à migrer.
Les deux approches peuvent être sécurisées. La différence est la testabilité : les règles d'accès dans un logiciel Symfony sont du code versionné, couvert par des tests automatisés. Une régression de sécurité est détectée avant la mise en production. Avec RLS, une politique mal formulée peut passer inaperçue.