Alternative Pipedrive / GUIDE DE MIGRATION
Exporter vos données depuis Pipedrive

Que vous exportiez vos données vous-même ou que vous fassiez appel à un prestataire, ce guide détaille chaque type de données présent dans votre CRM Pipedrive, comment les extraire et ce qui nécessite une attention particulière avant de changer d'outil.
LES DONNÉES
Ce que nous migrons depuis Pipedrive
Quitter Pipedrive ne signifie pas perdre vos données. Voici les types de données que SmartBooster analyse, extrait et migre vers votre logiciel sur mesure.
Affaires (deals)
Titre, valeur, étape, pipeline, probabilité et date de clôture prévue avec l'ensemble des champs personnalisés. Migré vers une table SQL avec clés étrangères vers contacts et organisations.
Contacts (Persons) et Organisations
Fiches contact et fiche entreprise avec leurs champs standard et personnalisés. Les relations entre personnes et organisations sont converties en clés étrangères dans le schéma cible.
Activités
Appels, emails, réunions et tâches liés aux affaires, contacts et organisations. Type, date, statut réalisé et compte rendu interne.
Produits et lignes de produit
Catalogue produit avec prix par devise et unité. Les lignes produit associées aux affaires forment une table de jointure avec quantité et prix négocié.
Notes et commentaires
Contenu des notes au format HTML lié aux affaires, contacts et organisations, avec auteur et horodatage.
Pipelines et étapes
Configuration des pipelines commerciaux : nom d'étape, probabilité et ordre. Remappée dans le nouveau cycle de vente lors de la migration.
Prospects (leads)
Contacts qualifiés dans la boîte de réception Leads, non encore convertis en affaires. Migrés avec leur source, leur valeur estimée et leurs labels.
Projets (Projects)
Suivi post-vente lié aux affaires gagnées : phases, responsables et dates cibles. Disponible uniquement sur les plans Growth et supérieurs.
Exporter vos données depuis l’interface Pipedrive
Avant tout développement, Pipedrive permet d’exporter vos données en XLSX depuis les paramètres du compte. C’est la première étape pour auditer vos données ou les transmettre à un prestataire.
Comment exporter depuis l’interface Pipedrive
Accédez à Paramètres (icône en bas à gauche) puis Exporter des données (Data Export). Pipedrive propose un export séparé pour chaque type d’objet : Deals, Organizations, People, Activities, Products, Notes et Leads. Chaque export génère un fichier XLSX avec les colonnes correspondant aux champs de l’objet.
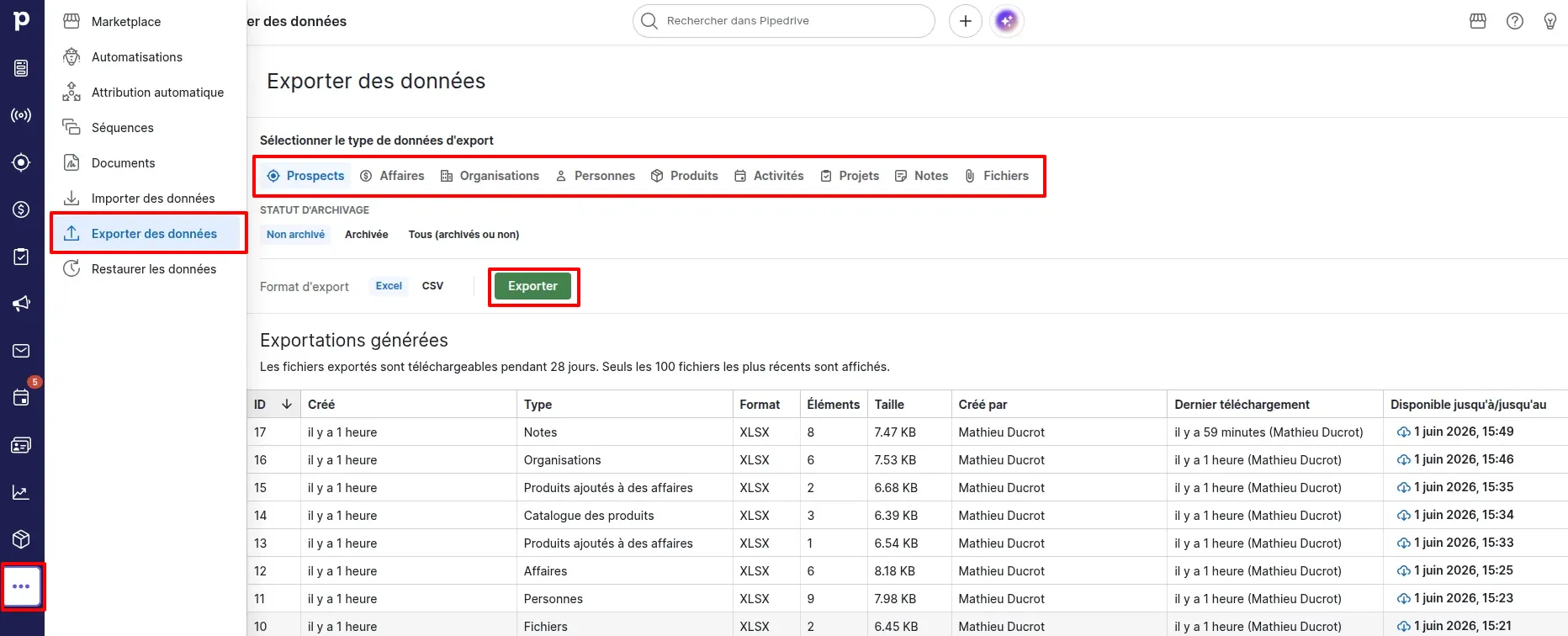
Points d’attention avec l’export interface :
- Les champs personnalisés sont inclus, mais leurs colonnes portent le libellé affiché dans l’interface, pas leur nom interne API. Cela complexifie le mapping lors de la migration.
Ce que l’export XLSX ne couvre pas
Pour une migration complète, l’export seul ne suffit pas. L’API REST Pipedrive est nécessaire pour récupérer les identifiants internes (essentiels pour reconstituer les relations), les lignes de produit associées aux affaires et les champs personnalisés avec leur nom API exact.
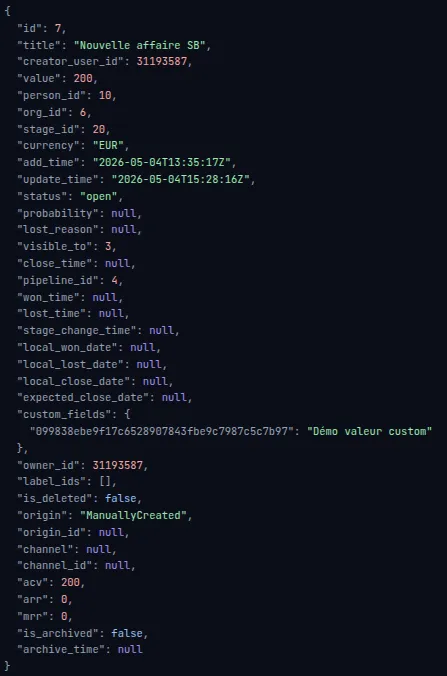
Affaires (Deals) : le pivot du modèle de données
Les affaires sont extraites via l’API Deals avec le endpoint /api/v2/deals
(pagination par cursor, recommandés pour les extractions volumineuses). Chaque deal contient :
| Champ Pipedrive | Description | Correspondance cible |
|---|---|---|
title | Intitulé de l’affaire | VARCHAR |
value | Valeur estimée | DECIMAL |
currency | Devise associée | Référence devise |
stage_id | Étape dans le pipeline | Clé étrangère vers étape |
pipeline_id | Pipeline concerné | Clé étrangère vers pipeline |
status | open / won / lost (les deals supprimés sont accessibles 30 jours via un endpoint dédié) | ENUM |
expected_close_date | Date de clôture prévue | DATE |
probability | Probabilité de conversion (%) | INT |
person_id | Contact principal lié | Clé étrangère |
org_id | Organisation liée | Clé étrangère |
owner_id | Commercial responsable | Clé étrangère vers utilisateur |
add_time, update_time | Dates de création et modification | DATETIME |
Les champs personnalisés des deals apparaissent comme des propriétés supplémentaires dans la
réponse API, identifiées par un hash (ex : abc123def456). Leur mapping est effectué en les
confrontant au schéma retourné par GET /api/v2/dealFields.
Extraction des Contacts et Organisations via l’API
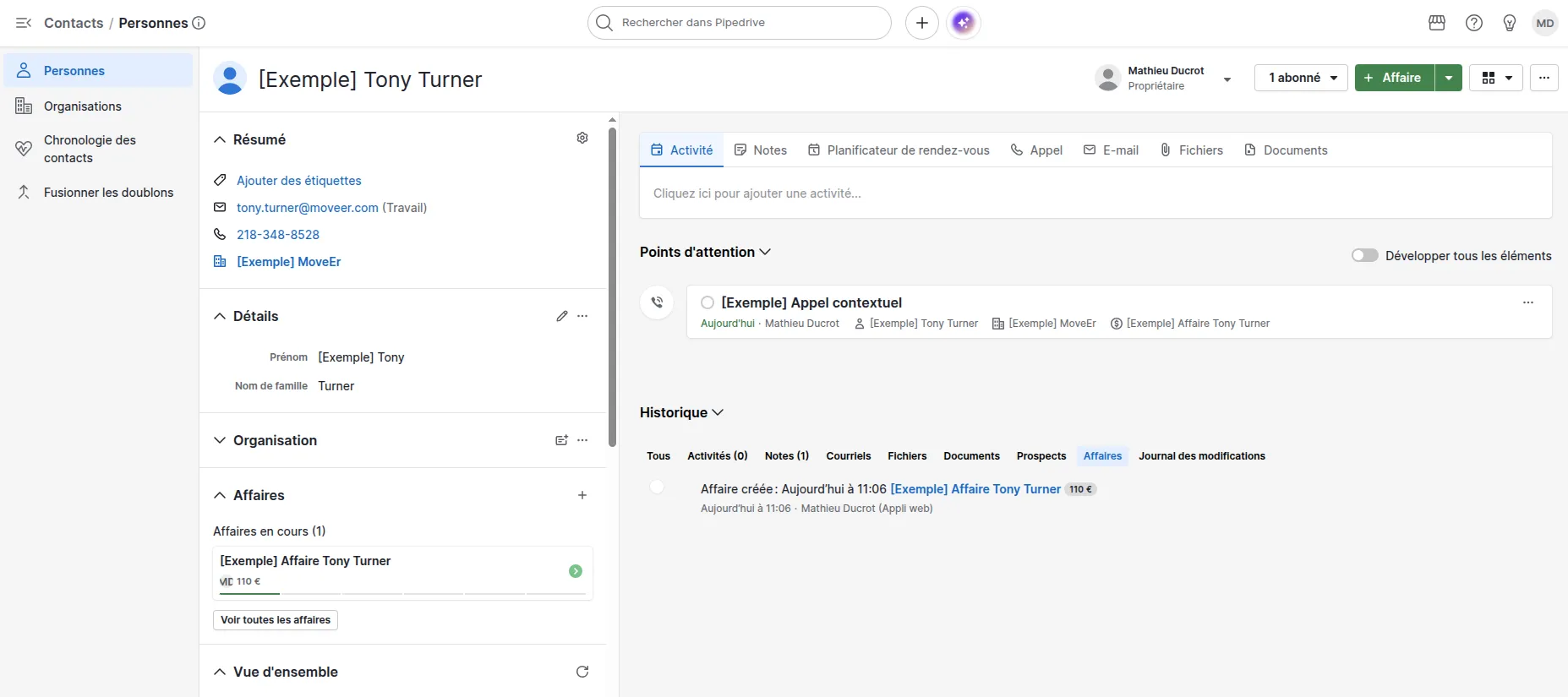
Persons (contacts)
Les contacts sont extraits via GET /api/v2/persons. Chaque fiche contact contient :
name: nom completemails: tableau d’adresses email (principale et secondaires)phones: tableau de numéros (fixe, mobile, travail)org_id: organisation liée (clé étrangère)owner_id: propriétaire du contact dans Pipedrive- Champs personnalisés accessibles via
GET /api/v2/personFields
Organizations (entreprises)
Les organisations sont extraites via GET /api/v2/organizations. Elles contiennent les coordonnées
de l’entreprise, son adresse et ses champs personnalisés (accessibles via GET /api/v2/organizationFields).
La relation Pipedrive est une personne liée à une organisation via org_id. Si un contact
est associé à plusieurs organisations (cas atypique), la relation principale est conservée et les
liaisons secondaires sont documentées avant la migration pour éviter toute perte de données.
Extraction des activités
Les activités couvrent tous les types d’interactions commerciales : appels, emails, réunions,
tâches et déjeuners. Elles sont extraites via GET /api/v2/activities.
| Champ | Description |
|---|---|
subject | Intitulé de l’activité |
type | call / email / meeting / task / deadline / lunch |
due_date, due_time | Date et heure d’échéance |
done | Activité réalisée (boolean) |
deal_id | Affaire associée |
person_id | Contact associé |
org_id | Organisation associée |
note | Compte rendu ou notes internes |
Pipedrive limite à 500 activités par requête avec pagination via cursor et limit.
Les activités représentent souvent le volume le plus important à migrer sur un compte actif
depuis plusieurs années.
Extraction des produits et lignes de produit
Catalogue produit
Le catalogue est extrait via GET /api/v2/products. Chaque produit contient un nom, une unité et
un tableau de prix par devise (prices : currency, price, cost). Les types de produit
et les champs personnalisés sont accessibles via GET /api/v2/productFields.
Lignes de produit liées aux affaires (Deal Products)
Les produits associés à une affaire sont récupérables via le endpoint GET /api/v2/deals/products : extraction groupée de toutes les lignes de produit de
plusieurs affaires en une seule requête.
Chaque ligne contient la quantité, le prix unitaire, la remise et le montant total. C’est cette association qui constitue le détail commercial de l’affaire.
Notes
Les notes sont extraites via GET /api/v1/notes. Chaque note contient son contenu au format HTML
(content), son auteur (user_id), ses associations (deal_id, person_id, org_id,
lead_id, project_id) et ses horodatages de création et de modification.
L’API permet de filtrer les notes par entité associée : toutes les notes d’une affaire, d’un contact, d’un lead ou d’un projet sont récupérables directement sans scanner l’intégralité des notes du compte.
Le contenu HTML des notes est converti en texte enrichi ou Markdown lors de la migration, selon les capacités du logiciel cible.
Extraction des prospects
Les prospects sont gérés dans la boîte de réception Leads et extraits via GET /api/v1/leads.
Chaque lead est rattaché soit à une personne soit à une organisation (selon la structure de
votre compte) et peut être converti en affaire. Les leads contiennent leur titre, leur valeur
estimée, leur source et leurs labels.
Ils sont migrés vers le logiciel cible soit comme des affaires en cours de qualification, soit dans un module dédié à la génération de pipeline, selon votre processus commercial réel.
Extraction des projets
Le module Projets est disponible à partir du plan Growth. Les projets sont extraits via
GET /api/v2/projects. Chaque projet est lié à une affaire gagnée et contient des phases, des tâches
et des membres assignés.
Si votre usage du module Projets est central à votre suivi post-vente, il fait l’objet d’une analyse spécifique lors du cadrage : les workflows peuvent être recréés avec plus de flexibilité dans un logiciel sur mesure.
Extraction des pipelines et étapes
La configuration des pipelines est extraite via GET /api/v2/pipelines et les étapes via GET /api/v2/stages.
Chaque étape contient son nom affiché (name), sa position dans le pipeline (order_nr) et
une probabilité de conversion (deal_probability) dont la valeur dépend de la configuration
choisie : certains comptes désactivent la probabilité par étape et la gèrent manuellement sur
chaque affaire, ce qui est analysé lors du cadrage avant migration.
Cette configuration est remappée dans le nouveau cycle de vente. Si vous avez plusieurs pipelines (pipeline standard et pipeline partenaires, par exemple), chaque pipeline est recréé séparément avec ses règles de progression.
Champs personnalisés (Custom Fields)
Pipedrive permet de créer des champs personnalisés sur les Deals, Persons, Organizations, Products
et Leads. Ces champs sont accessibles via les endpoints Fields correspondants :
| Objet | Endpoint |
|---|---|
| Deals | GET /api/v2/dealFields |
| Persons | GET /api/v2/personFields |
| Organizations | GET /api/v2/organizationFields |
| Products | GET /api/v2/productFields |
Types de champs et correspondances SQL
| Type Pipedrive | Correspondance cible |
|---|---|
varchar, text, varchar_auto | VARCHAR ou TEXT |
double, monetary | DECIMAL |
date, daterange, time, timerange | DATE ou DATETIME |
enum | ENUM ou table de référence |
set | Table de jointure |
user | Clé étrangère vers utilisateur |
org, people | Clé étrangère vers organisation / contact |
phone, address | Champ structuré ou VARCHAR |
Les champs de type set permettent de relier une affaire à plusieurs valeurs simultanément
(une liste à choix multiples). Ces relations sont converties en tables de jointure lors
de la migration, de la même façon que les multipleSelects d’Airtable.
Sur les endpoints v2, le paramètre custom_fields permet de limiter les champs personnalisés
retournés à une liste de 15 clés maximum. Utile pour des extractions ciblées sur des objets
avec de nombreux champs personnalisés.
Ce qui nécessite une décision avant la migration depuis Pipedrive
Certains éléments ne peuvent pas être migrés automatiquement :
- Les automatisations Pipedrive : déclencheurs et actions sont analysés et recréés en logique métier native (jobs planifiés, événements applicatifs, notifications)
- Les intégrations natives (Gmail, Google Meet, Slack, Aircall, Zapier) : reconnectées sur les nouvelles APIs du logiciel cible
- Les rapports et tableaux de bord : recréés dans le reporting sur mesure selon vos indicateurs réels, sans les métriques non utilisées
- Les formulaires Web Visitor : remplacés par les formulaires intégrés au nouveau logiciel
- Les séquences email : analysées et reconstruites en logique applicative
Ce qui peut rester dans Pipedrive
La migration n’est pas forcément totale. Certains usages peuvent coexister temporairement ou durablement avec le nouveau logiciel :
- Les pipelines d’équipes qui utilisent Pipedrive de façon autonome avec leurs propres données
- Les intégrations email (Gmail, Outlook) si elles restent pertinentes pour l’équipe commerciale
- L’application mobile Pipedrive pendant la transition, si le nouveau logiciel n’a pas encore de version mobile déployée
SmartBooster peut aussi développer un connecteur API pour synchroniser Pipedrive avec le nouveau logiciel, au lieu de le remplacer complètement.
Ce qu’un prestataire doit maîtriser pour migrer depuis Pipedrive
Si vous faites appel à un prestataire pour cette migration, voici les questions à poser pour évaluer sa rigueur avant de démarrer :
- Inventaire des champs personnalisés : le prestataire doit lister tous les
dealFields,personFieldsetorganizationFieldsavant d’écrire le moindre script de migration. - Mapping des relations : la chaîne deal vers person vers organization doit être cartographiée et validée avec vous avant l’extraction.
- Traitement des lignes de produit : la migration des Deal Products doit être prévue explicitement, pas laissée de côté comme dans un simple export XLSX.
- Environnement de recette dédié : la migration doit être testée sur un environnement isolé avec des données réelles, jamais directement en production.
- Plan de rollback : en cas d’anomalie détectée après la bascule, que se passe-t-il ? Votre compte Pipedrive doit rester accessible pendant une période de vérification.
Chez SmartBooster, ces points font partie du cadrage initial de chaque projet de migration.
Authentification à l’API Pipedrive
Pipedrive propose deux méthodes d’authentification :
- API Token : jeton personnel accessible dans les paramètres du compte (Settings > API). Transmis selon le mode d’accès de l’endpoint utilisé (paramètre de requête ou header selon la version de l’API). Recommandé pour une migration ponctuelle réalisée par votre équipe ou un prestataire de confiance.
- OAuth 2.0 : flux standard pour les intégrations multi-comptes. Recommandé si le connecteur doit être utilisé sur plusieurs comptes Pipedrive ou par des utilisateurs tiers.
Un accès en lecture seule suffit pour une migration. Aucune permission d’écriture n’est nécessaire lors de l’extraction des données.
Références techniques Pipedrive
RENDEZ-VOUS DÉCOUVERTE GRATUIT
30 minutes, gratuites, sans engagement
Décrivez votre besoin directement à Nicolas. On écoute votre situation et on vous dit si et comment on peut vous aider.
Appel de 30 min → Analyse gratuite → Proposition sous 5 jours

Pour aller plus loin
Approfondir votre réflexion
Découvrez pourquoi un logiciel sur mesure peut remplacer Pipedrive et comment SmartBooster accompagne cette transition.
Symfony, Vue.js, Clever Cloud : les technologies que nous utilisons pour développer des logiciels robustes et maintenables.
Vous avez un projet ?
Contactez-nous pour savoir comment nous pouvons vous aider.